🕹️ 手刻強化學習
從 Q-table 到 DQN 與策略梯度全部親手刻,理解每一步;再借 stable-baselines3 加速,最後訓練 agent 玩自製接水果遊戲
 01 入門
01 入門 強化學習的世界觀 · 第一個 gym 環境
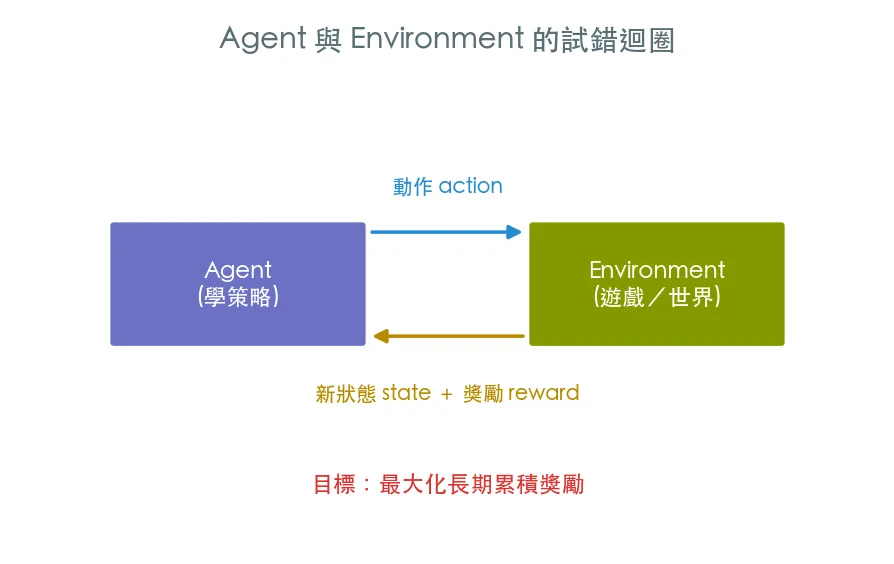
強化學習不看正確答案,而是讓 agent 在環境裡試錯、靠獎勵自己摸索。這堂課用經典的 CartPole 把 agent ⇄ environment 的迴圈跑起來,認識 gymnasium 的標準介面。
 02 入門
02 入門 手刻 Q-learning · 一張表學會走迷宮
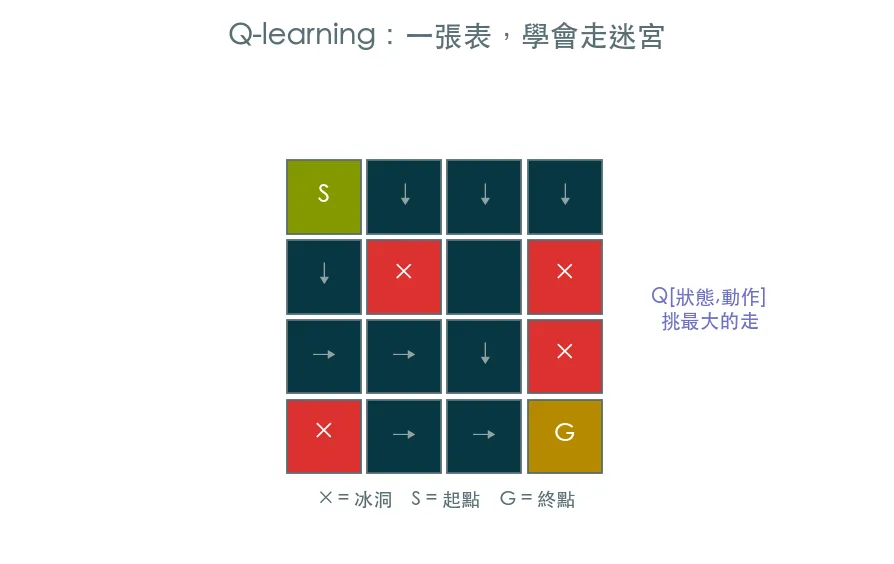
最經典也最好懂的 RL 演算法。用一張 Q 表記住「在每個狀態做每個動作有多好」,搭配 Bellman 更新與 epsilon-greedy,讓 agent 在 FrozenLake 上學會從起點走到終點。
 03 進階
03 進階 從 Q 表到 DQN · 用神經網路逼近 Q
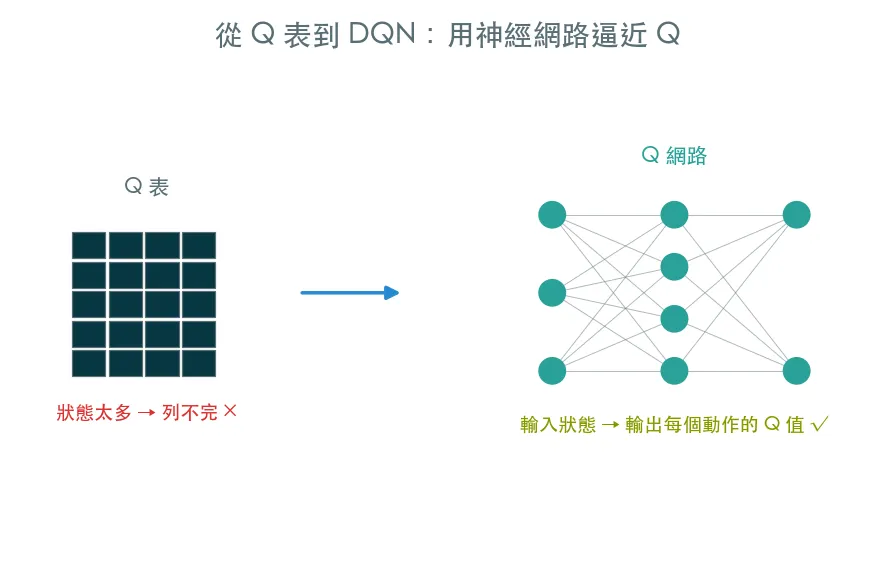
Q 表碰到連續或巨大的狀態空間就爆了。DQN 的點子:用一個神經網路取代那張表。這堂課親手刻一個迷你 DQN,配上經驗回放與 target network,把它在 CartPole 上練起來。
 04 進階
04 進階 站在巨人肩上 · stable-baselines3
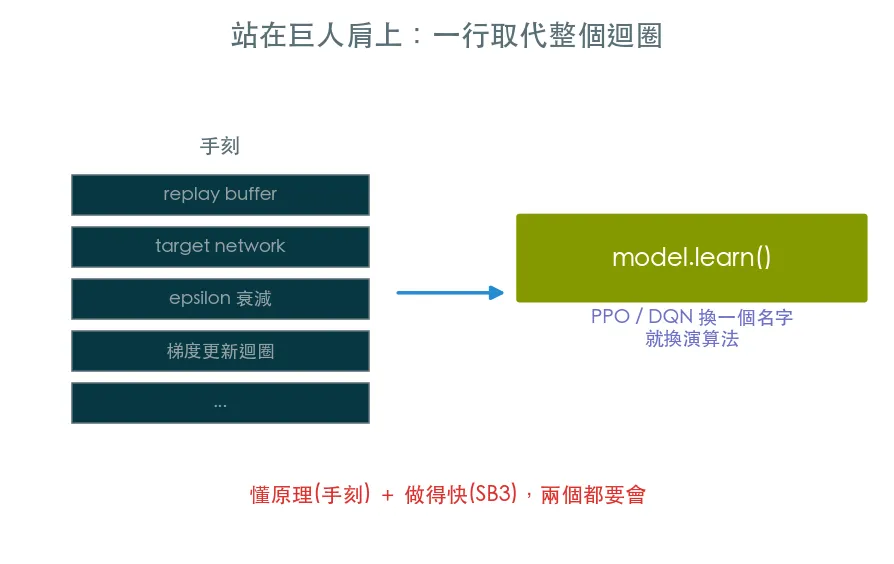
手刻 DQN 讓你懂原理,但做專案沒人每次重寫訓練迴圈。stable-baselines3 把 DQN、PPO 等演算法封裝成幾行就能用的可靠實作。一行 model.learn() 取代整個迴圈,並用 TensorBoard 監控訓練。
 05 進階
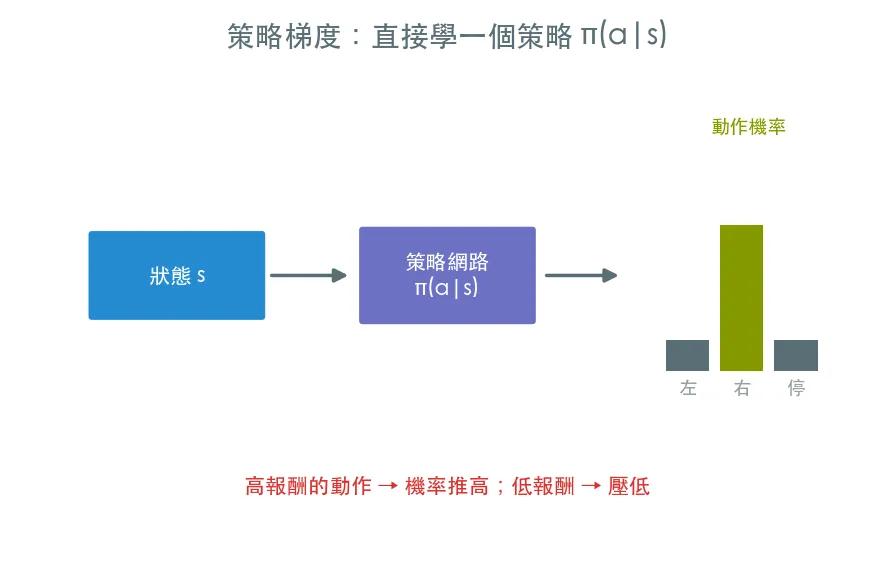
05 進階 策略梯度 · 直接學一個策略
DQN 那一家先學 Q 值再推動作;策略梯度反過來,直接把策略參數化成神經網路,讓帶來高報酬的動作機率變大。這堂課手刻 REINFORCE——PPO、A2C 等現代演算法的共同祖先。
 06 進階
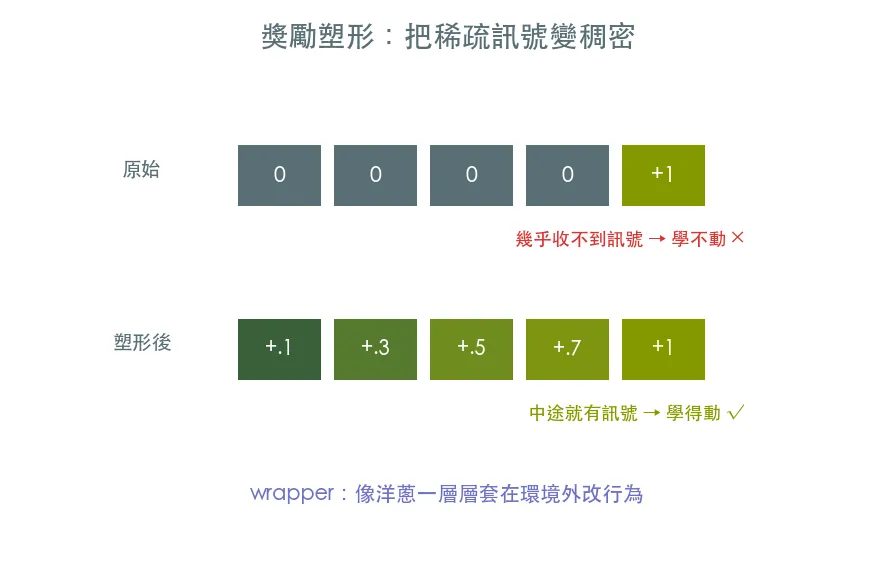
06 進階 獎勵塑形與環境包裝器
獎勵很稀疏時 agent 收不到訊號、根本學不動。兩個救星:環境包裝器(像洋蔥一層層套在環境外改行為)與獎勵塑形(自己加中途獎勵,把稀疏訊號變稠密)。在難纏的 MountainCar 上實戰。
 07 進階
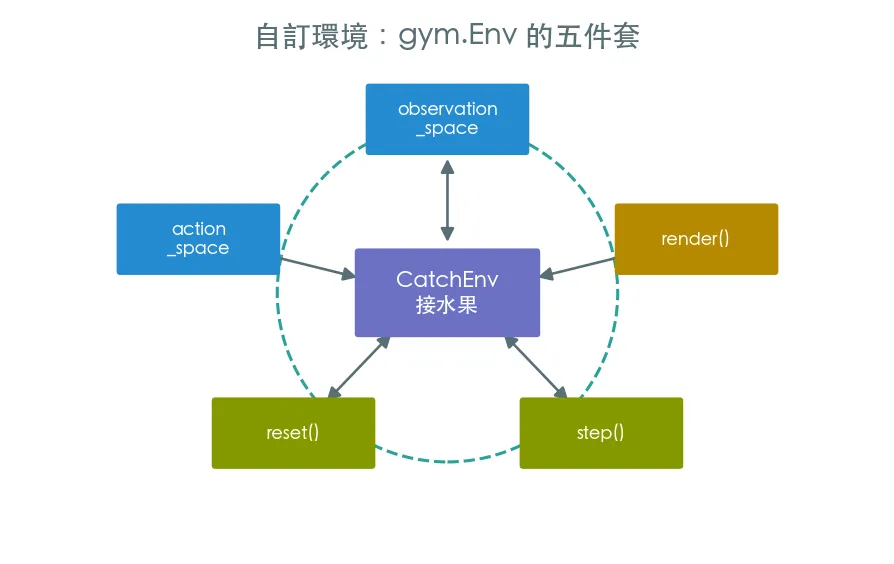
07 進階 自訂環境 · 把小遊戲包成 gymnasium
前六課都在用別人寫好的環境,這課反過來自己刻一個。只要實作 gymnasium 的五件套(兩個 space + reset/step/render),任何遊戲都能變成 RL 環境。我們做一個接水果小遊戲。
 08 專題
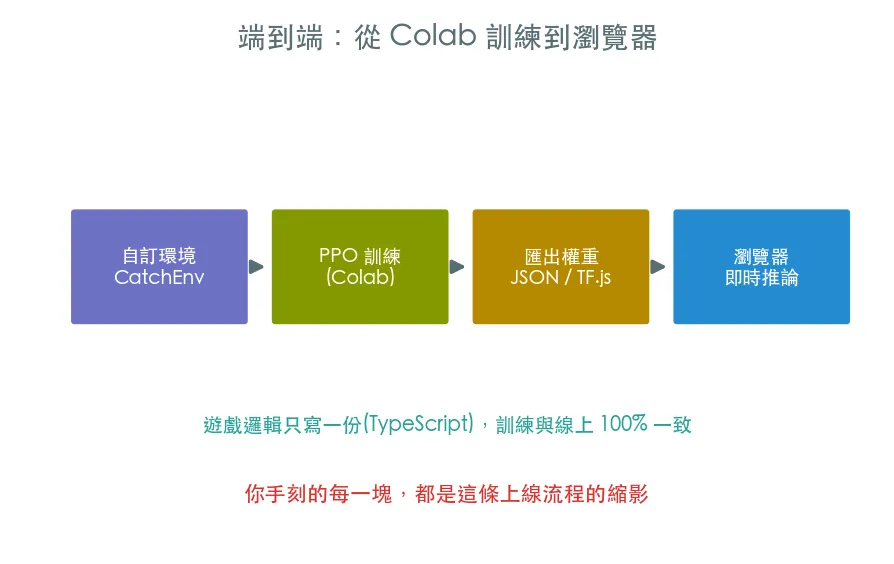
08 專題 端到端實戰 · 訓練 agent 玩接水果
整條軌道的收尾。拿第七課自訂的 CatchEnv,用 stable-baselines3 訓練一個真的會接水果的 agent,評估、存檔,最後聊聊怎麼把訓練好的模型搬進瀏覽器——正是本站遊戲區 RL 的做法。
留言 0
留言載入中…