07 進階
自訂環境 · 把小遊戲包成 gymnasium
前六課都在用別人寫好的環境,這課反過來自己刻一個。只要實作 gymnasium 的五件套(兩個 space + reset/step/render),任何遊戲都能變成 RL 環境。我們做一個接水果小遊戲。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
前六課,你都在用別人寫好的環境(CartPole、FrozenLake、MountainCar)。這一課反過來——自己刻一個。這是把 RL 用在你自己的問題上的關鍵一步:只要實作 gymnasium 的標準介面,任何遊戲、任何模擬、任何最佳化問題,都能變成一個 RL 環境,接上 stable-baselines3 開訓。
練習題:接水果
我們做一個 接水果(Catch) 小遊戲:底部一塊木板,接住從上方一格一格掉下來的水果。麻雀雖小,五臟俱全。
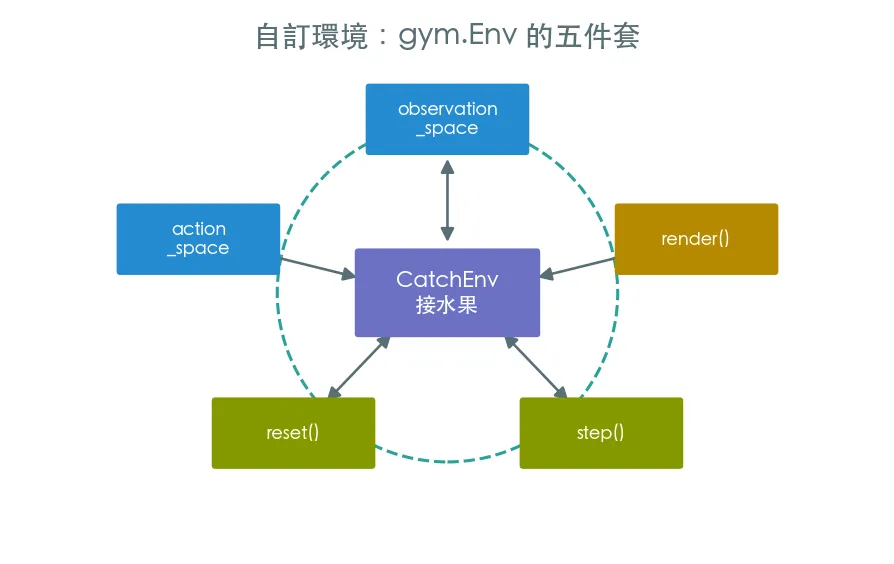
gymnasium 環境的五件套
繼承
gym.Env,定義這五件事:
observation_space:agent 看得到什麼(這裡:木板位置、水果 x、水果 y)action_space:agent 能做什麼(左移 / 不動 / 右移)reset():回到初始狀態,回(obs, info)step(action):走一步,回(obs, reward, terminated, truncated, info)render():畫出當前畫面
這堂課你會學到
- 親手寫一個合規的
gym.Env子類別:CatchEnv - 觀察設計的關鍵:要讓 agent「看得到做決定所需的資訊」——這裡是木板與水果的相對位置
- 獎勵設計:接到 +1、漏接 −1
- 用官方的
check_env驗證介面合規——自訂環境上線前必跑的健檢
觀察設計:RL 最重要的工程決定之一
同一個遊戲,觀察給得好不好,訓練難度天差地遠。如果只給 agent 看「水果的絕對座標」而不給木板位置,它根本無從判斷該往哪移。好的觀察讓問題變簡單,壞的觀察讓再強的演算法也學不動。這堂課的 CatchEnv 觀察刻意設計得乾淨,下一課它就能被輕鬆訓練起來。
💡 這套「把遊戲包成環境」的能力,正是本站遊戲區讓 AI 玩自家遊戲的基礎。下一課壓軸,我們就訓練一個 agent 真的學會玩這個接水果遊戲。
#rl
#gymnasium
#custom-env
#game
留言 0
留言載入中…