🌫️ 擴散模型生成影像
手刻 forward/reverse diffusion 在 MNIST 上生成數字,再用 diffusers 玩 Stable Diffusion 文生圖、img2img 與 LoRA
 01 入門
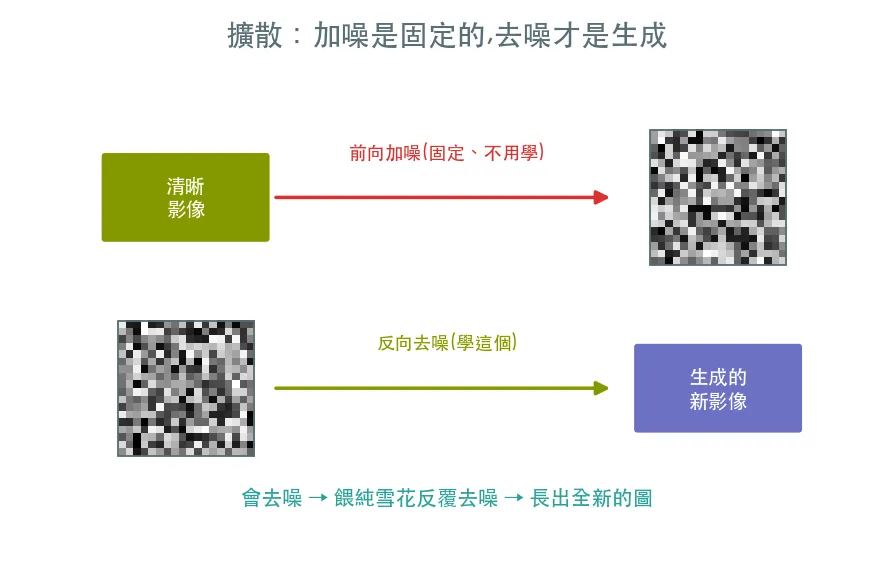
01 入門 生成模型的世界觀 · 從加噪到去噪
前面的軌道讓模型辨識影像,這條軌道讓模型創造影像。比較 VAE/GAN/Diffusion 三條路線,並親眼看擴散的前向過程——把一張數字一步步加噪成雪花,建立「破壞是為了學會重建」的心智模型。
 02 進階
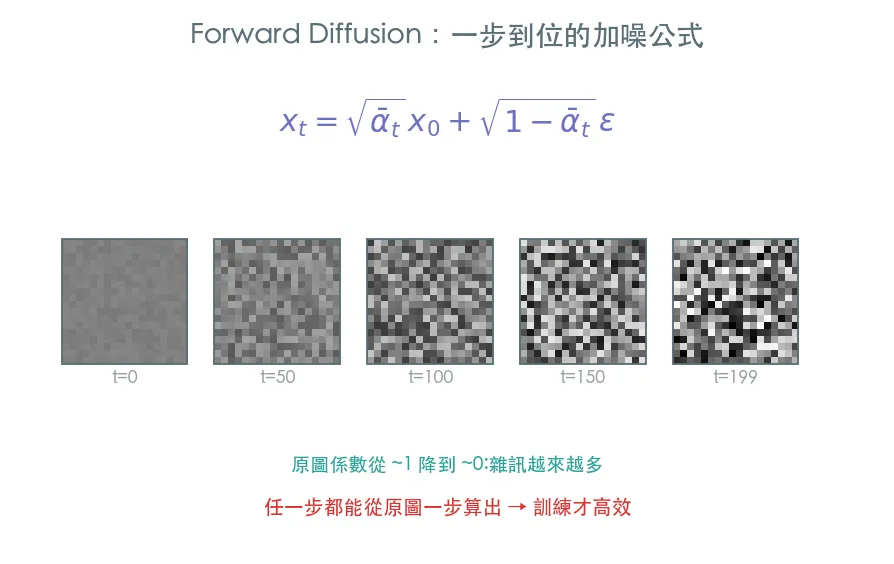
02 進階 手刻 Forward Diffusion · 加噪的數學
真正的擴散模型用精心設計的加噪排程,而且有個漂亮性質:任何一步 x_t 都能從原圖一步算出來,不必跑 t 次迴圈。親手實作 beta 排程與 closed-form 的 q_sample。
 03 進階
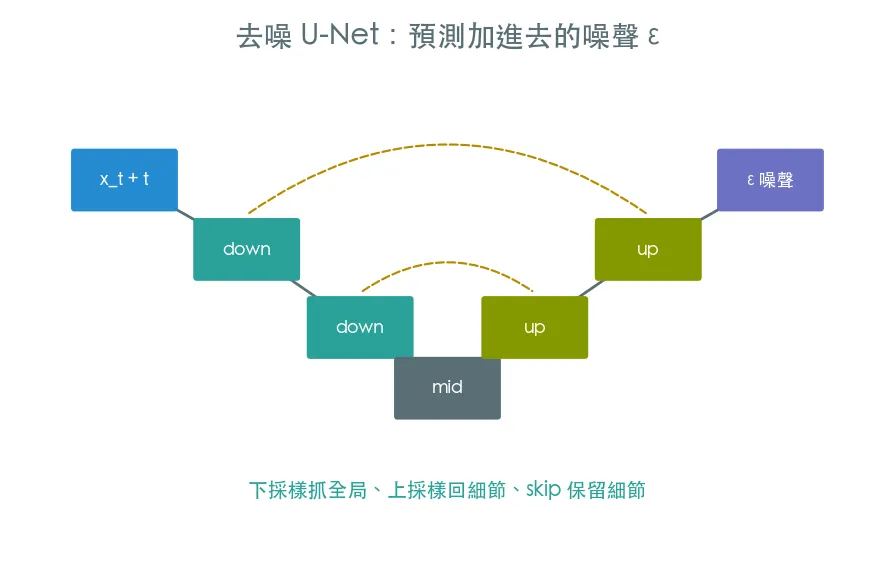
03 進階 手刻去噪 U-Net · 訓練模型生成數字
整條軌道的核心課。前向加噪不用學,要學的是反向去噪:訓練一個 U-Net 看著加噪圖預測「當初加進去的噪聲」。學會預測噪聲,餵純雪花反覆去噪,就生出全新的數字。
 04 進階
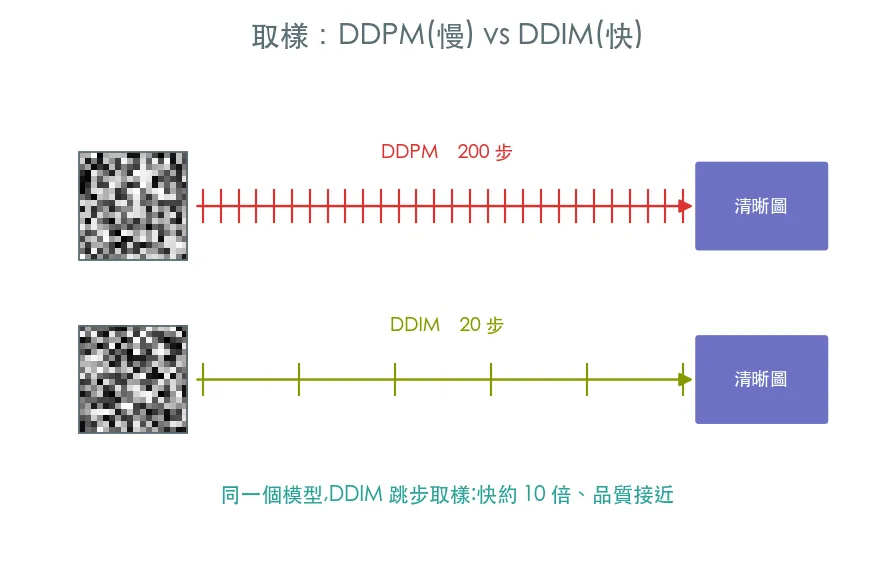
04 進階 取樣 · DDPM vs DDIM 與去噪軌跡
DDPM 老實走完全部 200 步,慢;DDIM 把取樣變成確定性、可以跳著走,只要 20 步就生出差不多的圖,快十倍。比較兩者,並把「雪花 → 數字」的逐步顯影過程畫出來。
 05 進階
05 進階 文字條件 · 一句話如何導引生成
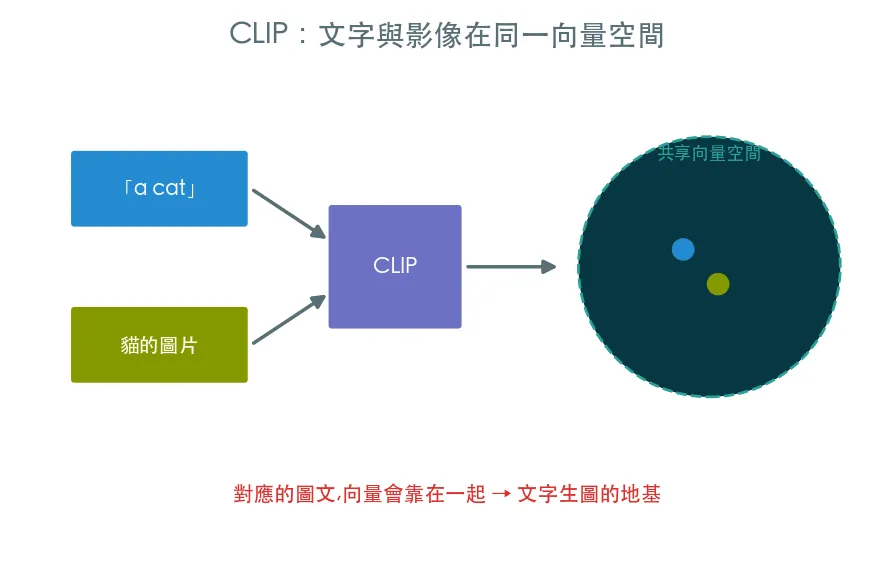
我們的迷你模型只會隨機生數字。真正的 Stable Diffusion 能聽懂「一隻沙灘上的柯基」,靠的是文字條件:CLIP 把 prompt 變成向量、cross-attention 注入去噪。親眼見證 CLIP 把文字與影像對齊。
 06 進階
06 進階 用 diffusers 跑 Stable Diffusion
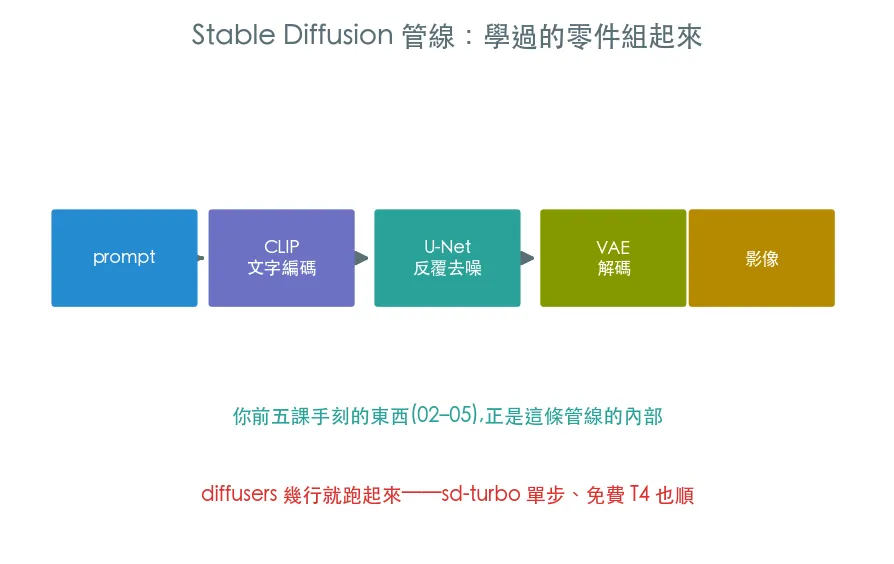
手刻迷你版讓你懂了原理,現在站上巨人肩膀:用 Hugging Face diffusers 跑真正的 Stable Diffusion,打一句話生一張圖。用 sd-turbo——一步生圖、免費 T4 跑得順、免授權手續。
 07 進階
07 進階 控制生成 · img2img、inpainting、LoRA
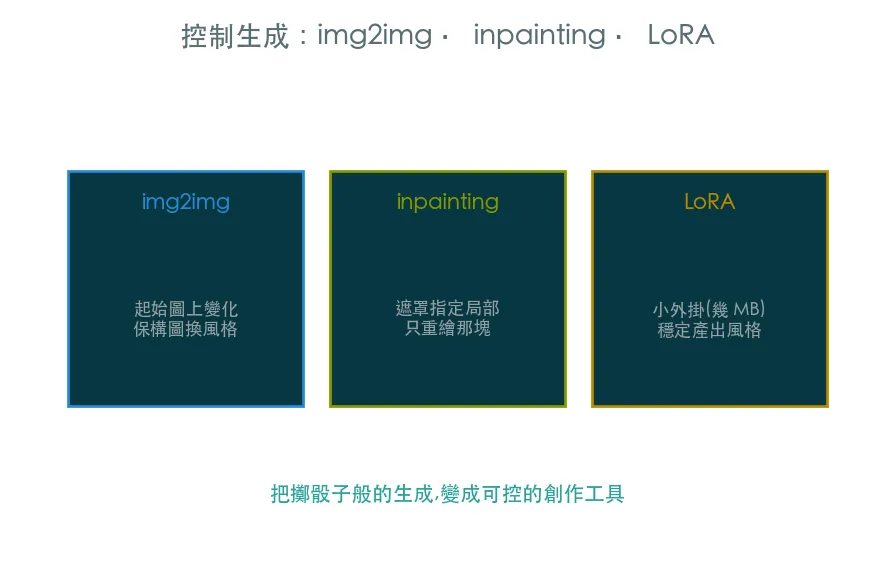
純文字生圖像擲骰子。真正用在創作上需要控制:img2img(在起始圖上變化)、inpainting(只重繪局部)、LoRA(風格外掛)。三招把擲骰子般的生成變成可控的創作工具。
 08 專題
08 專題 端到端實戰 · 做一個圖像生成小工具
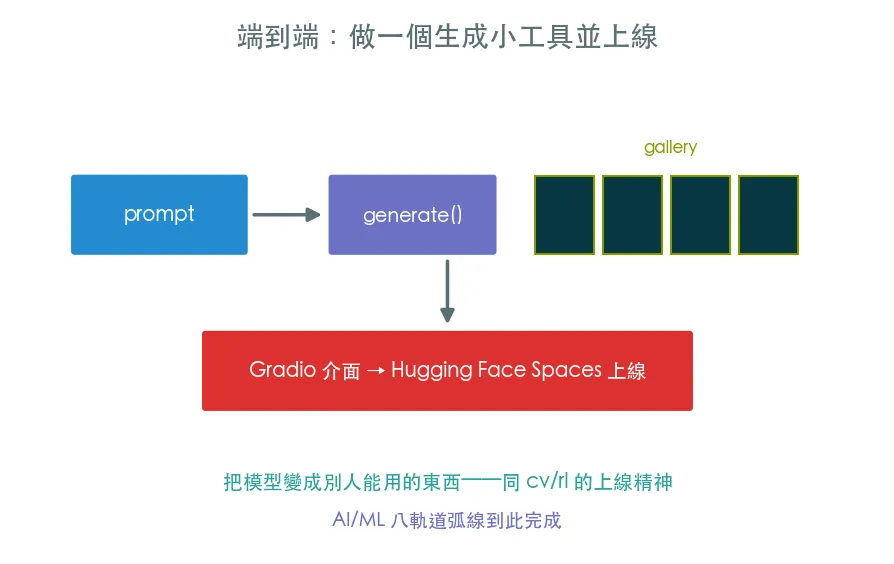
整條軌道的收尾,也是整個 AI/ML 弧線的最後一哩。把生成包成好用的 generate(prompt) 函式、批次比較不同 prompt,最後聊怎麼用 Gradio + Hugging Face Spaces 把它分享成一個任何人能用的網頁工具。
留言 0
留言載入中…