手刻去噪 U-Net · 訓練模型生成數字
整條軌道的核心課。前向加噪不用學,要學的是反向去噪:訓練一個 U-Net 看著加噪圖預測「當初加進去的噪聲」。學會預測噪聲,餵純雪花反覆去噪,就生出全新的數字。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
整條軌道的核心課。前向加噪不用學;要學的是反向去噪。做法出奇地簡單:
核心:預測噪聲
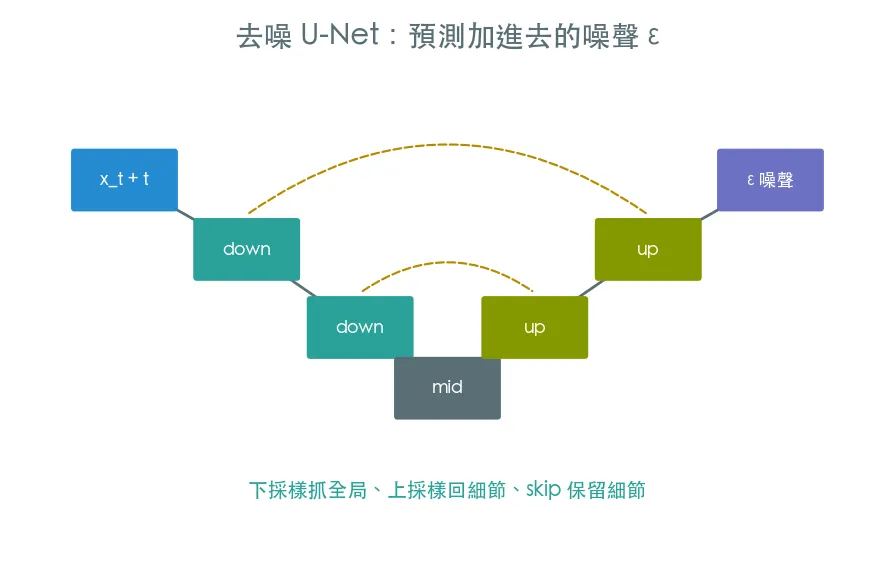
訓練一個神經網路,看著加噪圖
x_t和時間步t,把當初加進去的噪聲ε預測出來。損失就是「預測的噪聲」和「真正的噪聲」的 MSE。
學會預測噪聲,等於學會了「這張圖該往哪個方向去噪」。我們用一個迷你 U-Net 來當這個去噪器。
這堂課你會學到
- 親手搭一個 U-Net:下採樣抓全局、上採樣回細節、skip 連接保留細節
- 怎麼把時間步 t 用正弦編碼餵進去,讓模型知道在去噪的哪個階段
- 完整的訓練迴圈:隨機抽 t → 加噪 → 預測噪聲 → MSE → 更新
- 生成:餵純雪花、跑完整反向過程,看數字「長」出來
為什麼 U-Net?
去噪要同時看「全局結構」(這是個 8 還是 3)與「局部細節」(筆畫邊緣)。U-Net 的下採樣抓全局、上採樣回細節,中間的 skip 連接把細節資訊接回去——天生適合這種「輸入輸出同尺寸、又要兼顧大小尺度」的任務。從 Stable Diffusion 到醫療影像分割,U-Net 無所不在。
功能爛沒關係,重在跑通
你生出的數字也許歪歪扭扭、糊糊的——完全沒關係。這條軌道的目標(同 llm 軌道)是讓你親手跑通 Stable Diffusion 的核心機制:加噪、預測噪聲、反向生成。懂了這個迴圈,幾十億參數的 SD 對你就不再是黑魔法,只是同樣的機制放大而已。
⚠️ loss 卡著不動,但圖在變好——這不是 bug
第一次訓練很多人會嚇到:loss 掉到某個值(約 0.7 上下)之後就幾乎不動了,看起來像訓練停擺。
這是正常的。我們的損失是「預測噪聲」對「真噪聲」的 MSE,而噪聲本質上有一大塊是無法預測的隨機——loss 永遠到不了 0,卡在某個下限才是對的。判斷模型有沒有在學,不要只盯 loss 數字,要看生成的圖有沒有越來越像數字。同理,訓練到一半去取樣,結果偏糊、偏雪花也不奇怪:擴散模型本來就要訓練夠久才會清晰,中途糊是過程,不是壞掉。
💡 模型只有約 46 萬參數,MNIST 上 5 個 epoch、T4 幾分鐘就能生出可辨認的數字。下一課,我們讓生成快十倍(DDIM),並把去噪的逐步軌跡畫出來看。
留言 0
留言載入中…