👁️ 深度電腦視覺
假設你已會 CNN 基礎,直接做視覺進階主題:遷移學習、資料增強、YOLO 物件偵測、影像分割、Grad-CAM
 01 入門
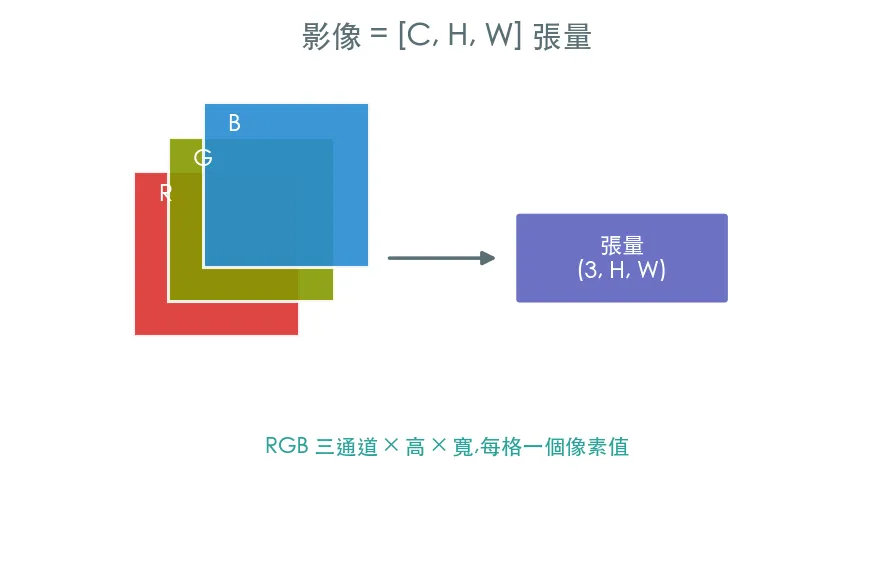
01 入門 影像即張量 · torchvision 的入口
在電腦眼裡,一張彩色影像就是一個 [C,H,W] 張量。這堂課用 torchvision 載入 CIFAR-10,看懂影像的形狀、像素範圍,以及正規化這個視覺模型幾乎必做的前處理。
 02 入門
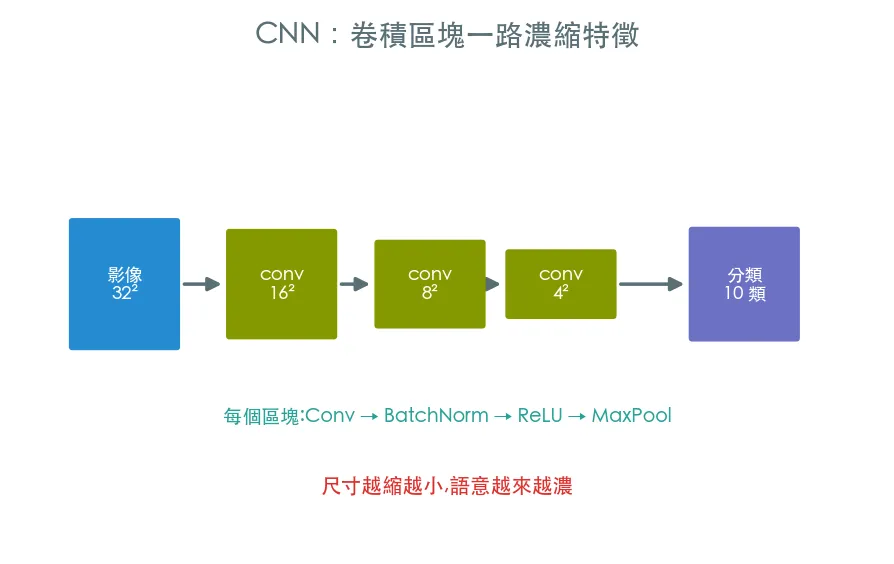
02 入門 在 CIFAR-10 上訓練一個 CNN
從 pytorch 軌道的灰階 MNIST,升級到彩色、更難的 CIFAR-10,用上現代 CNN 的標準配備:Conv→BatchNorm→ReLU 堆疊、MaxPool 降尺寸、Dropout 抗過擬合。
 03 進階
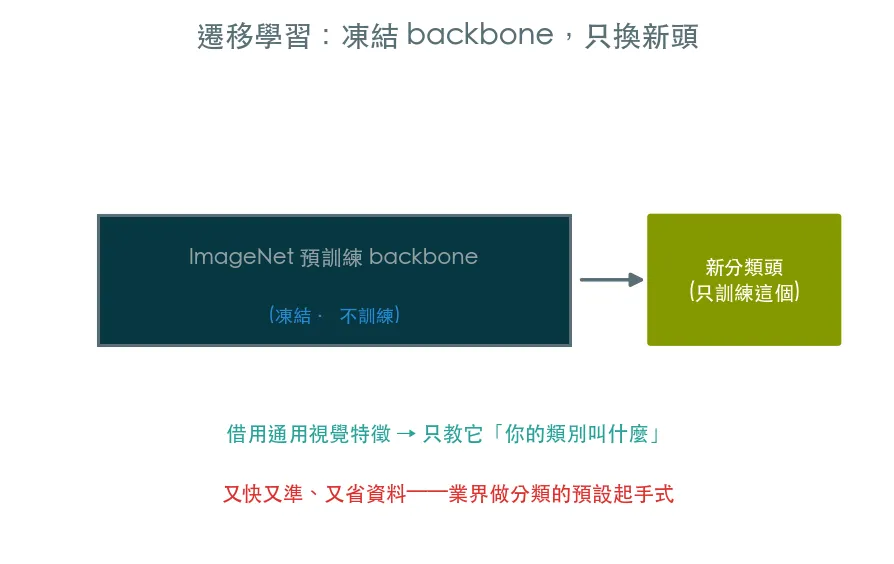
03 進階 遷移學習 · 站在 ImageNet 的肩上
從零訓練 CNN 要大量資料與算力。遷移學習拿 ImageNet 預訓練模型,凍結已學會通用視覺特徵的 backbone,只換掉分類頭微調——又快又準,是業界做影像分類的預設起手式。
 04 進階
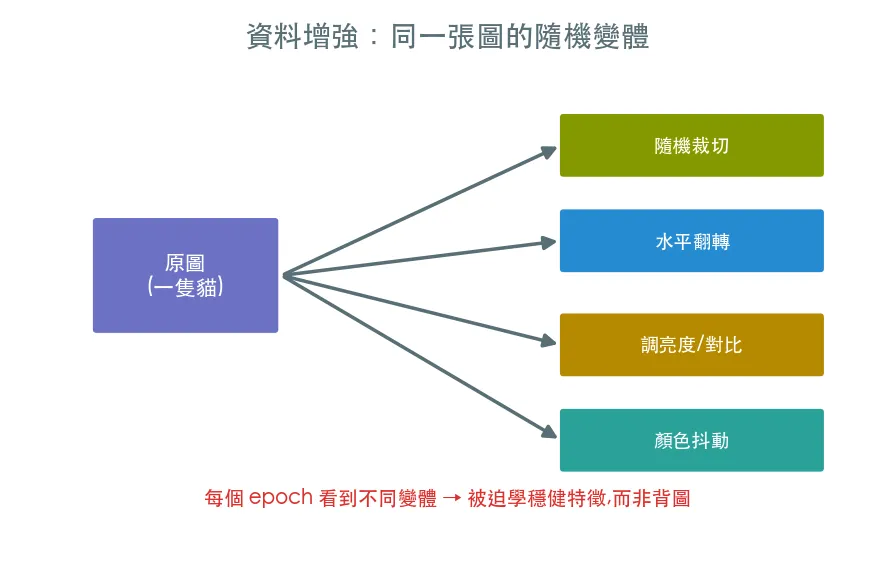
04 進階 資料增強 · 對抗過擬合
模型在訓練集很準、測試集卻爛掉,就是過擬合。資料增強用隨機裁切、翻轉、調色讓模型每個 epoch 看到同一張圖的不同變體,被迫學到穩健特徵而不是背圖——視覺領域最有效的正則化。
 05 進階
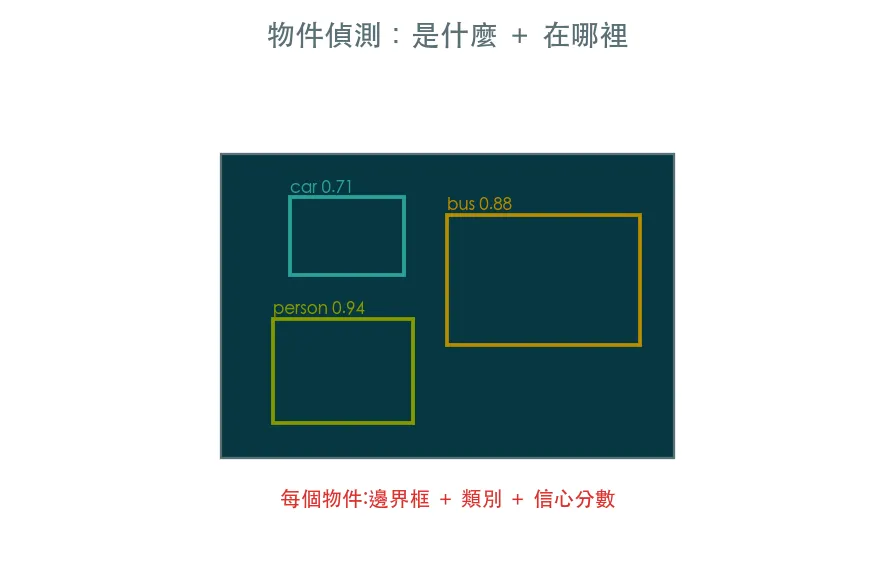
05 進階 物件偵測 · 不只是什麼,還要在哪裡
分類一張圖回一個標籤,但真實場景一張圖常有很多東西。物件偵測同時回答有什麼、在哪裡——框出每個物件的邊界框、類別與信心。用業界最當紅的 YOLO 開箱即用做推論。
 06 進階
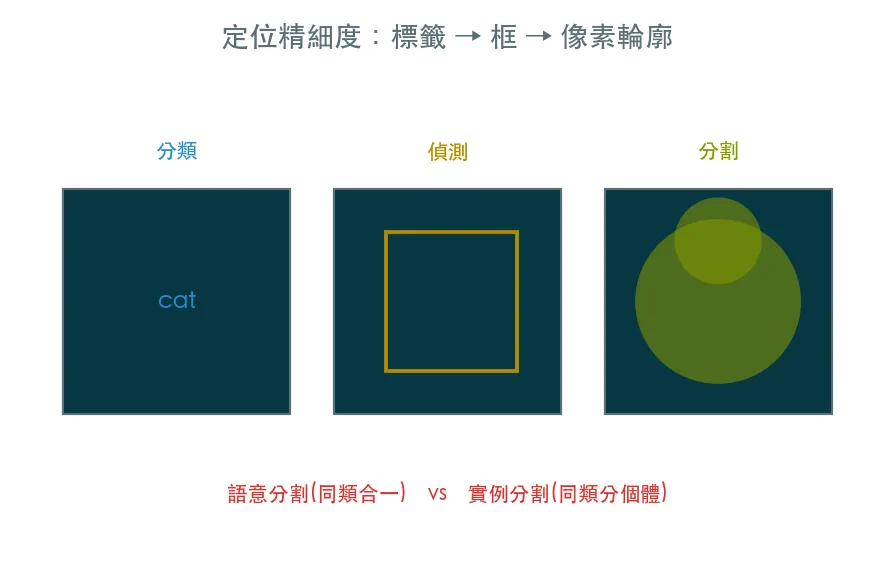
06 進階 影像分割 · 逐像素看懂畫面
偵測畫的是方框,方框裡仍混著背景。影像分割替每一個像素分類,精確切出物件輪廓。分語意分割(同類合一)與實例分割(同類分個體),用 YOLO-seg 實作實例分割。
 07 進階
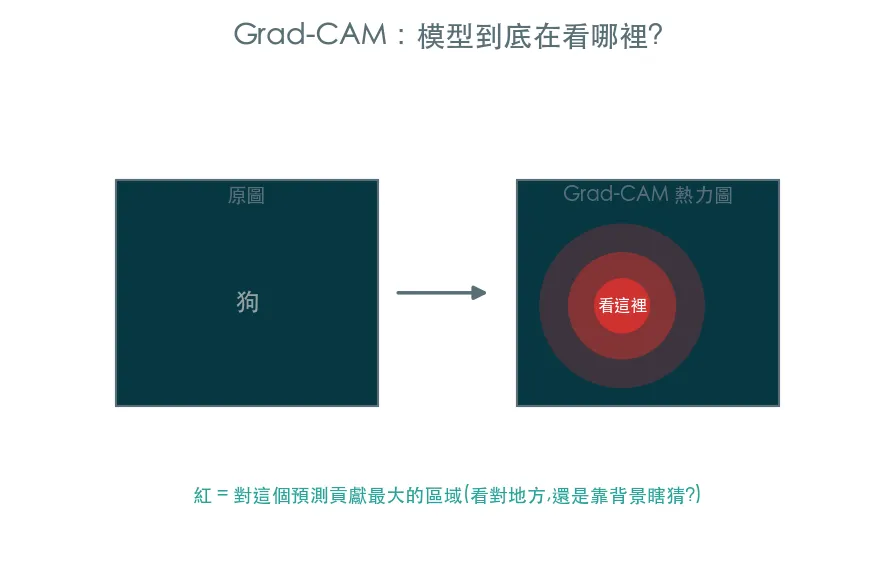
07 進階 Grad-CAM · 模型到底在看哪裡
CNN 說這是一隻狗、信心 98%,但它是看了狗的臉,還是看了背景的草地剛好猜對?Grad-CAM 用最後一層卷積的梯度,畫出影像上哪些區域對預測貢獻最大——打開 CNN 黑盒子。
 08 專題
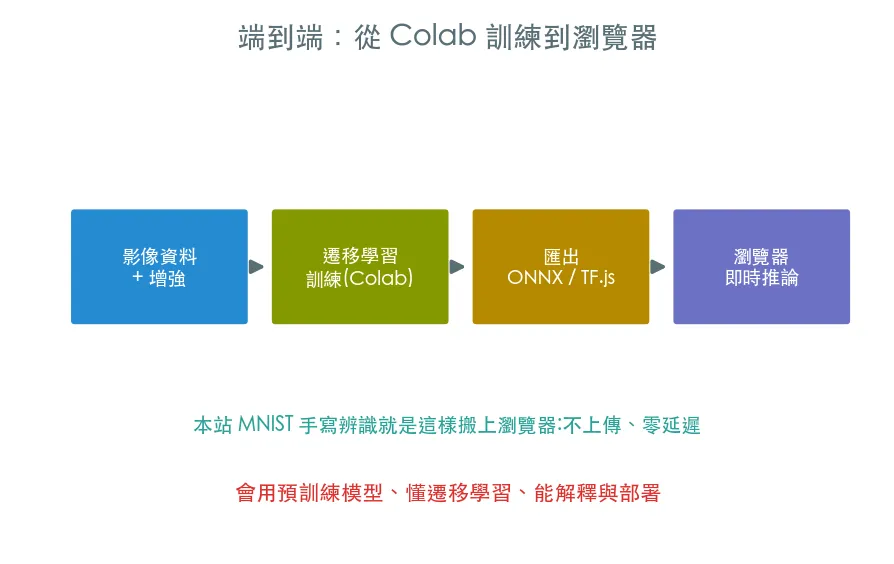
08 專題 端到端實戰 · 完整影像分類專案
整條軌道的收尾。把遷移學習 + 資料增強串成一個完整流程:訓練分類器、對單張圖做 Top-3 推論、存檔,最後聊怎麼把模型匯出成 ONNX/TF.js 部署到瀏覽器——呼應本站 MNIST 手寫辨識的做法。
留言 0
留言載入中…