資料增強 · 對抗過擬合
模型在訓練集很準、測試集卻爛掉,就是過擬合。資料增強用隨機裁切、翻轉、調色讓模型每個 epoch 看到同一張圖的不同變體,被迫學到穩健特徵而不是背圖——視覺領域最有效的正則化。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
模型在訓練集上很準、在測試集上卻爛掉——這就是過擬合:它把訓練圖「背」起來了,而不是學到通則。視覺領域對抗過擬合最有效的武器,就是資料增強。
核心點子
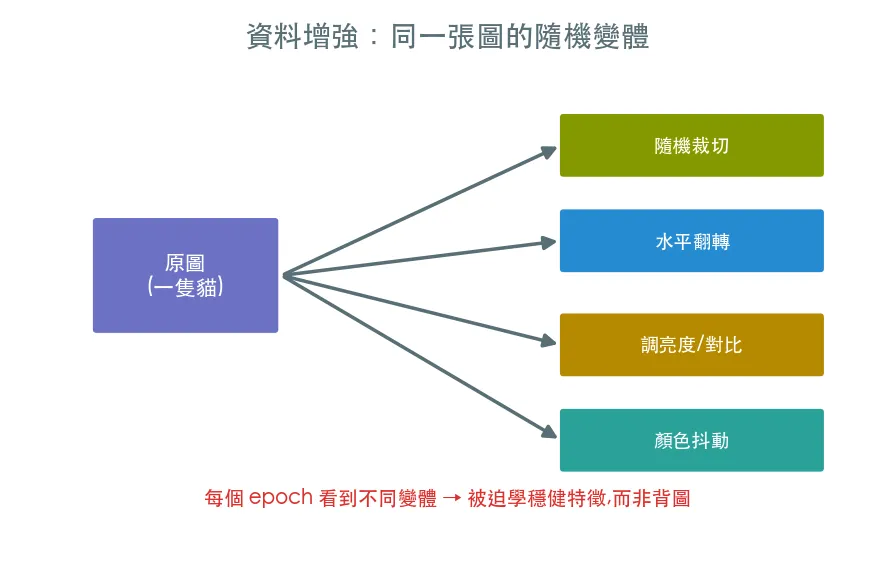
每次訓練時,把影像隨機裁切、翻轉、調色一下。模型每個 epoch 看到的都是「同一張圖的不同變體」,等於免費擴增了資料,被迫學到真正穩健的特徵,而不是死記某張圖的長相。
一隻貓不管被裁掉一角、左右翻轉、還是調暗一點,都還是貓。逼模型在這些變化下都答對,它學到的就是「貓的本質」,而非「這張貓圖的像素」。
這堂課你會學到
- 組一條增強管線:
RandomCrop、RandomHorizontalFlip、ColorJitter - 親眼看同一張圖的 8 個隨機變體——這正是模型每個 epoch 看到的
- 過擬合的徵兆:訓練準確率 ≫ 測試準確率,兩者拉開的那道縫
- 一條鐵則:增強只用於訓練集,測試集保持原樣(評估才公平)
增強是「免費」的正則化
比起蒐集更多真實資料,資料增強幾乎零成本,卻能顯著縮小過擬合的縫。它和上一課的遷移學習是標準組合:預訓練模型給你好的起點,資料增強讓你不會在小資料上過擬合。兩者搭起來,就是業界訓練視覺模型的日常配方。
⚠️ 加了增強,訓練準確率反而下降——這是對的
直覺上「資料變多模型該更準」,但你會看到開了增強後訓練準確率不升反降,容易以為增強幫倒忙。
這正是增強在發揮作用。每個 epoch 看到的都是被裁切、翻轉、調色過的變體,題目變難了,訓練準確率當然下降。真正要看的是測試準確率——它通常會上升,訓練與測試之間那道縫也會縮小。訓練分數低一點、測試分數高一點,才是「沒在背圖、真的學會」的健康徵兆。
💡 進階增強(Mixup、CutMix、RandAugment、AutoAugment)效果更猛,
torchvision.transforms多半已內建。但小心別增強過頭——把貓轉到認不出來,反而會傷害學習。
留言 0
留言載入中…