05 進階
過擬合與正則化
神經網路參數多、能力強,特別容易過擬合。先製造過擬合給你看,再用 dropout 與 weight decay 把它壓下去。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
神經網路參數多、能力強,所以特別容易過擬合——把訓練資料背得滾瓜爛熟,對沒看過的資料卻很差。這堂課先製造過擬合給你看,再用 dropout 和 weight decay 把它壓下去。
這堂課你會學到
- 用「訓練 vs 測試」準確率曲線看見過擬合
- 用 dropout 隨機關閉神經元,逼網路別死背
- 用 weight decay(L2)懲罰過大的權重
- 知道 data augmentation 的概念
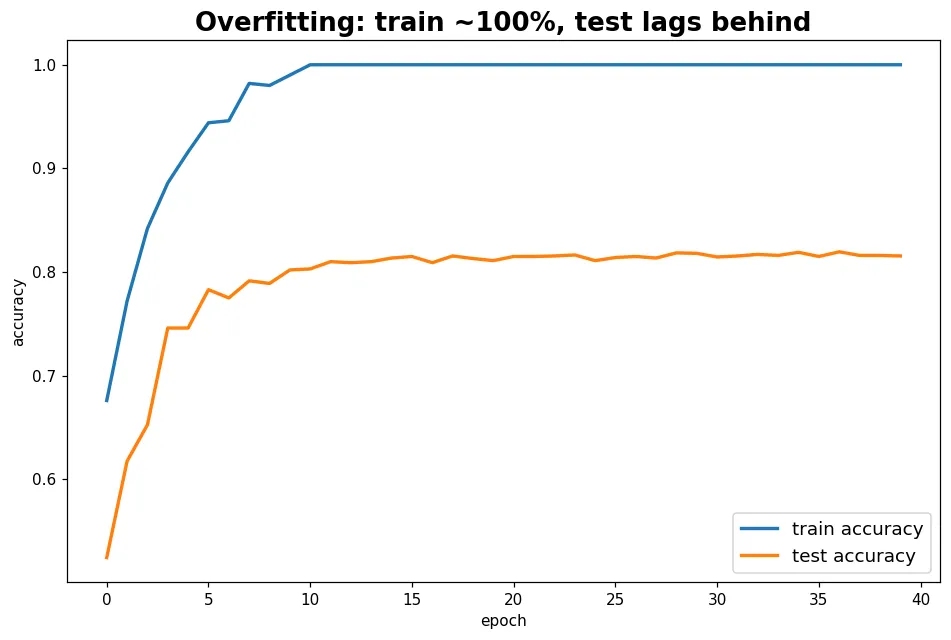
看見那道鴻溝
預覽圖是經典的過擬合長相:只用 500 筆資料、跑很多輪,訓練準確率衝到 ~100%,測試卻卡在低點——兩條線之間的鴻溝就是過擬合。
對付它有三招:
- Dropout:訓練時隨機把一部分神經元歸零,逼網路不能依賴特定幾個神經元、學更穩健的特徵。
- Weight decay:在 loss 裡加一項懲罰大權重(L2),讓模型更平滑。
- Data augmentation:對訓練影像隨機平移、旋轉、翻轉,等於免費變出更多樣本,是視覺任務的標配。
加上正則化後,訓練準確率不再貼到 100%,但測試準確率提升——犧牲一點背書能力,換來更好的泛化。
👉 在 Colab 裡把 dropout 調到 0.7,看測試準確率是更好還是反而變差(正則化過頭)。
#pytorch
#overfitting
#dropout
#weight-decay
#regularization
留言 0
留言載入中…