06 進階
用 GPU 加速
深度學習慢,是因為有海量矩陣運算。GPU 能平行處理,常常快上幾十倍。學會寫裝置無關的程式,並親手量一次加速。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
深度學習慢,是因為有海量的矩陣運算。GPU 能平行處理這些運算,常常快上幾十倍。這堂課教你寫裝置無關的程式,並親手量一次 GPU 的加速。
這堂課你會學到
- 偵測可用裝置(CUDA / Apple MPS / CPU)並寫出裝置無關的程式
- 理解 GPU 為何適合神經網路
- 親手 benchmark CPU vs GPU 的矩陣運算
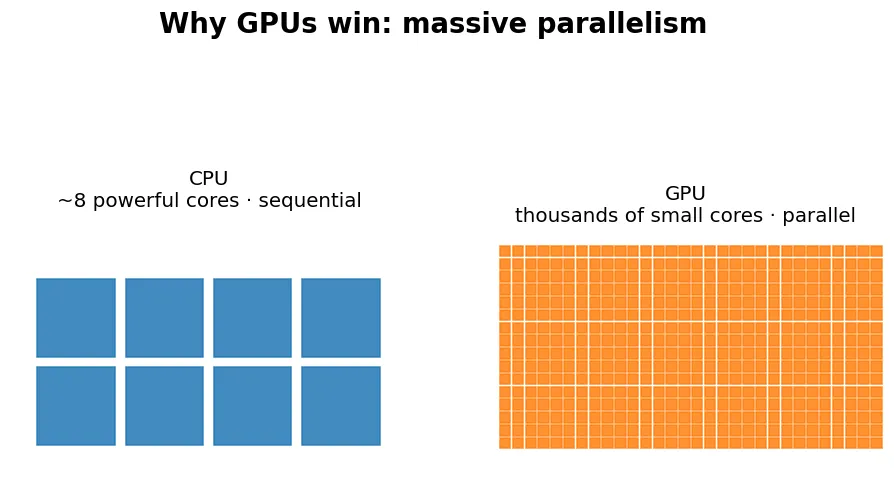
為什麼 GPU 快?
預覽圖說明了一切:CPU 有少數幾個強核心、循序處理;GPU 有數千個小核心,能同時算成千上萬個乘加。神經網路的核心正是大量矩陣相乘,矩陣越大、模型越大,GPU 的優勢越明顯。
寫法上的訣竅只有一句:把模型和每個 batch 的資料都 .to(device),其餘程式碼一字不改——同一份程式就能在 CPU 與 GPU 上跑。
在 Colab:執行階段 → 變更執行階段類型 → 選 GPU(T4),免費。
誠實提醒:Mac 的 MPS 在「單一中等運算」上未必比 CPU 快(啟動/傳輸成本),真正的加速在 Colab 的 CUDA GPU + 大模型整段訓練時才顯著。
👉 在 Colab 開 GPU,把第 04 課的 CNN 用全部 6 萬筆 MNIST 訓練,比 CPU 快多少。
#pytorch
#gpu
#cuda
#mps
#performance
留言 0
留言載入中…