🧠 scikit-learn 入門
統一的 fit/predict 節奏、分類與迴歸、Pipeline、模型評估、樹模型到端到端實戰
 01 入門
01 入門 scikit-learn 的世界觀
幾十種模型長一個樣子——學會 fit / predict / transform 這套節奏,你換任何模型都不用重學。先把這個統一的世界觀建好。
 02 入門
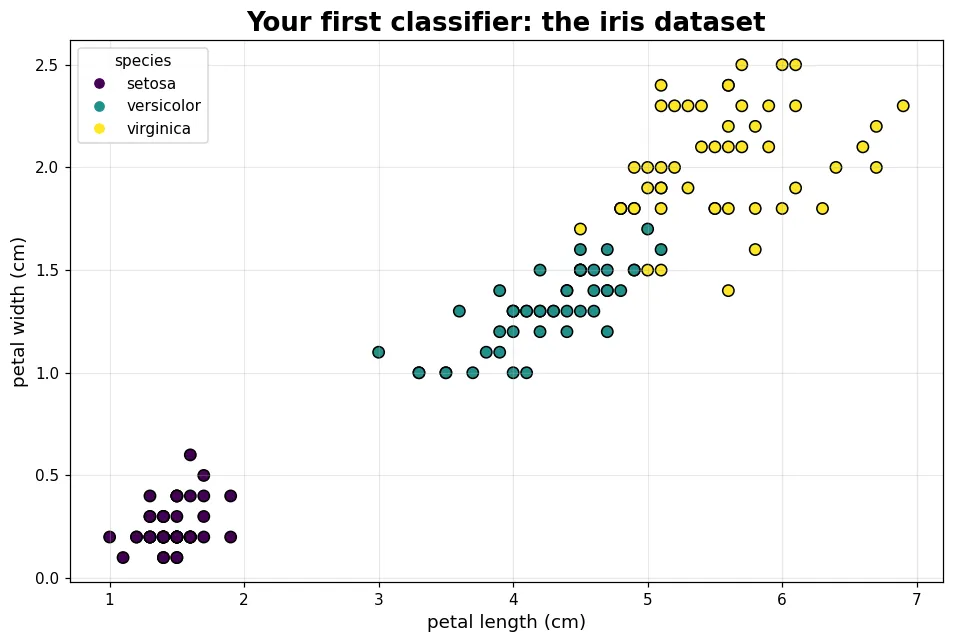
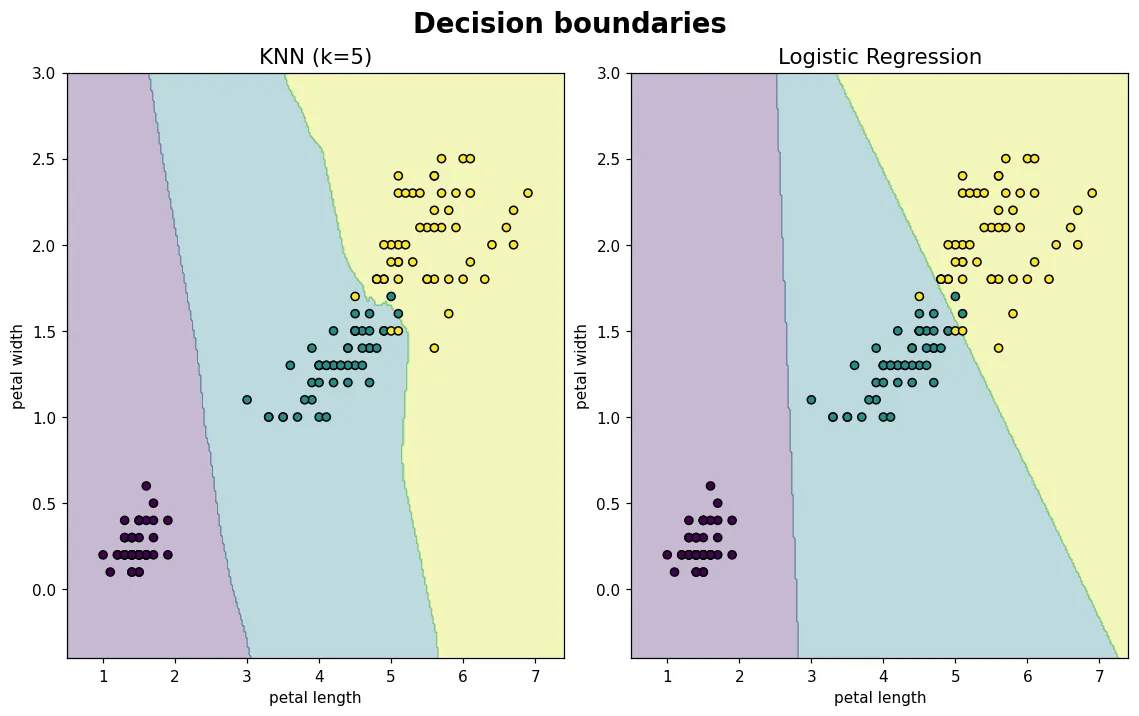
02 入門 分類:把決策邊界畫出來
比較 KNN 與邏輯迴歸兩個分類器,並把模型腦中的『決策邊界』畫出來——看它到底把空間怎麼切,一眼看懂模型的假設。
 03 入門
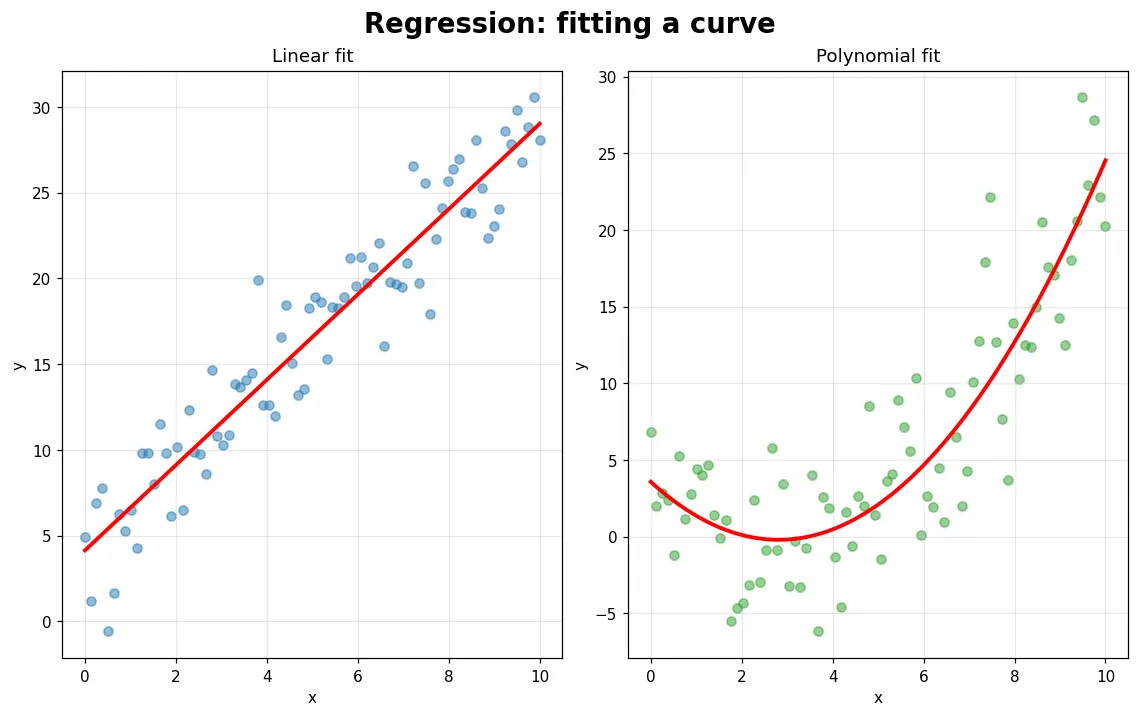
03 入門 迴歸:預測連續數值
從『猜哪一類』換成『預測一個數字』。線性與多項式迴歸、用 MSE / R² 評估、用殘差圖診斷模型有沒有抓住規律。
 04 進階
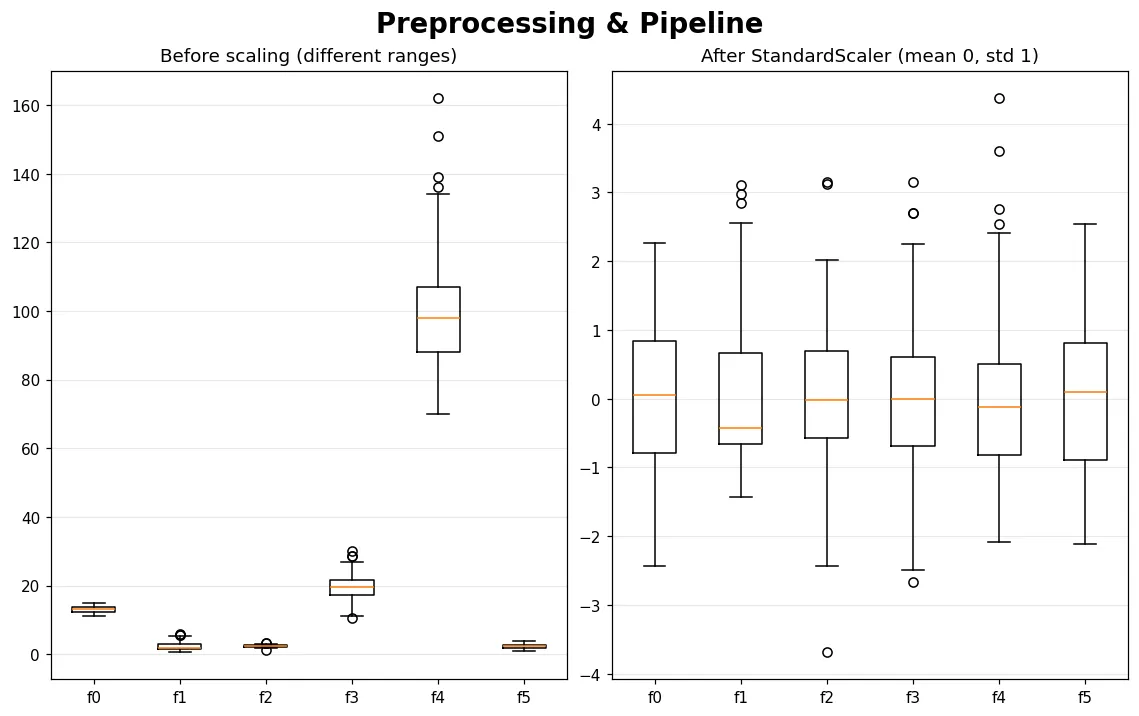
04 進階 前處理與 Pipeline
真實資料很少能直接餵給模型。學會用 StandardScaler 標準化、用 Pipeline 把前處理和模型綁成一體,並避開新手最常踩的『資料洩漏』陷阱。
 05 進階
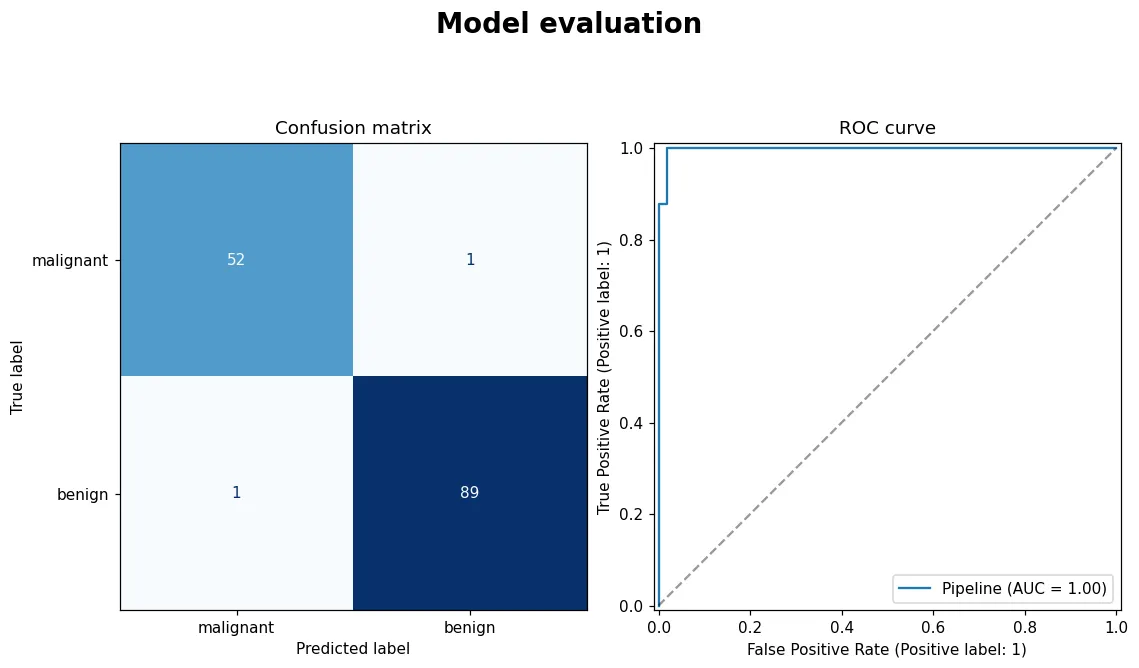
05 進階 模型評估:別只看準確率
『準確率 95%』可能是個騙局。學會用交叉驗證估得更穩,用混淆矩陣、precision / recall、ROC / AUC 看清模型真正的能力。
 06 進階
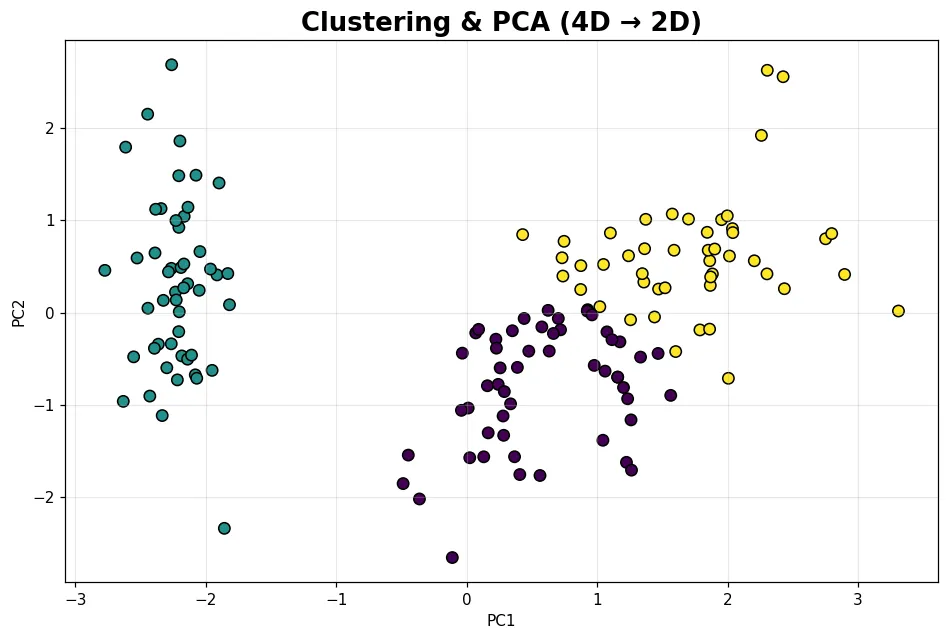
06 進階 非監督式學習:分群與降維
沒有答案,照樣能找出結構。用 KMeans 自動分群、用 PCA 把高維資料壓到 2D 看清楚,見證群集從資料本身浮現。
 07 進階
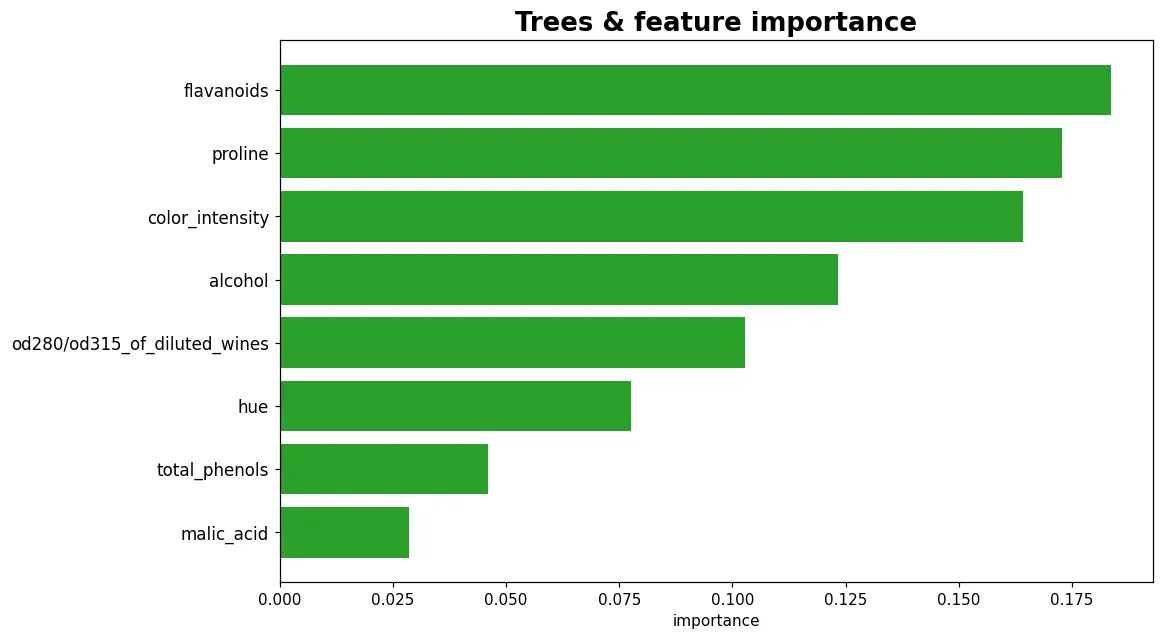
07 進階 樹模型與特徵重要性
決策樹用是非題做判斷,人看得懂、還告訴你哪些特徵最重要。把很多棵樹合起來投票,就是橫掃表格資料的隨機森林。
 08 專題
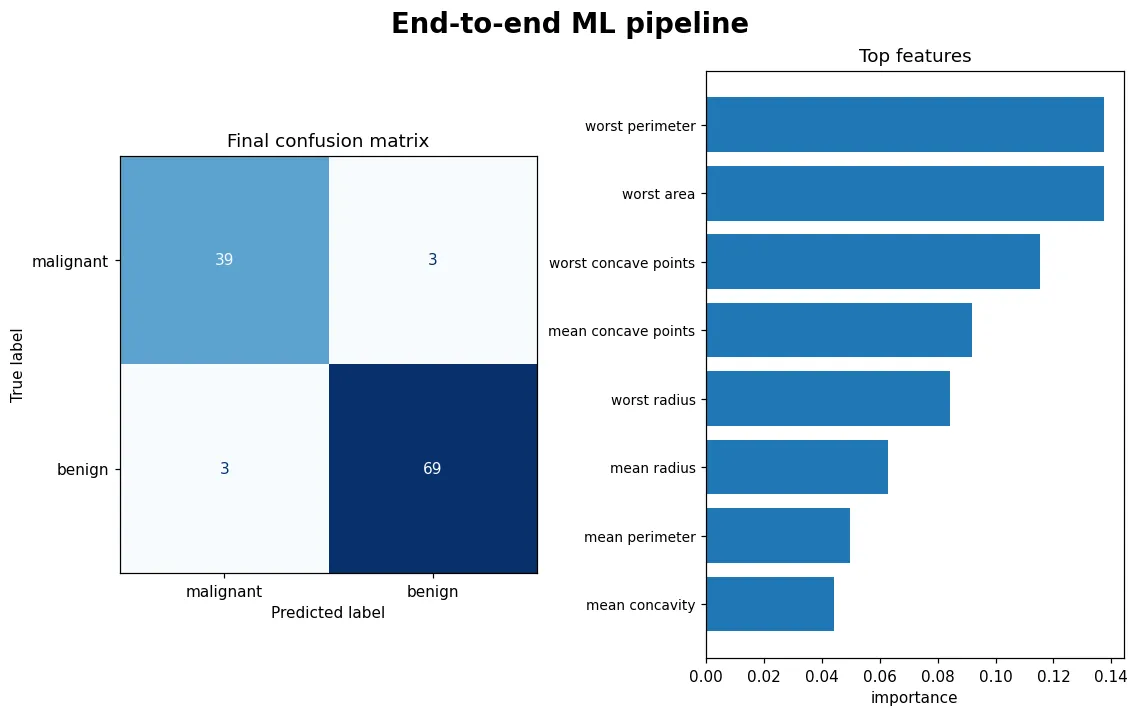
08 專題 完整流程實戰
把前七課的招式全部串起來,走一遍真實的機器學習流程:理解資料 → 切分 → Pipeline 前處理 → 交叉驗證 → GridSearch 調參 → 測試集驗收 → 解讀結果。
留言 0
留言載入中…