08 專題
完整流程實戰
把前七課的招式全部串起來,走一遍真實的機器學習流程:理解資料 → 切分 → Pipeline 前處理 → 交叉驗證 → GridSearch 調參 → 測試集驗收 → 解讀結果。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
學完一身招式,這堂課把它們串成一條完整的實戰流程。用乳癌診斷資料集,走一遍資料科學家拿到新資料時該有的工作節奏——這也是整個 scikit-learn 模組的收尾。
這堂課你會學到
- 串起完整流程:資料 → Pipeline → 調參 → 評估 → 解讀
- 用
GridSearchCV自動尋找最佳超參數 - 在被藏起來的測試集上做最終、誠實的驗收
- 用混淆矩陣與特徵重要性產出結論,而非只丟一個分數
機器學習的標準工作流程
把這條流程刻進肌肉記憶,拿到任何資料都能套:
- 理解資料 —— 形狀、類別分布、有沒有缺值
- 切分 —— 測試集先藏好,絕不偷看
- Pipeline —— 前處理 + 模型綁成一體,自動防資料洩漏
- 交叉驗證 + 調參 —— 只在訓練集上用
GridSearchCV找最佳設定 - 最終驗收 —— 測試集只開封一次,看混淆矩陣 / report / AUC
- 解讀 —— 用特徵重要性等工具產出洞察
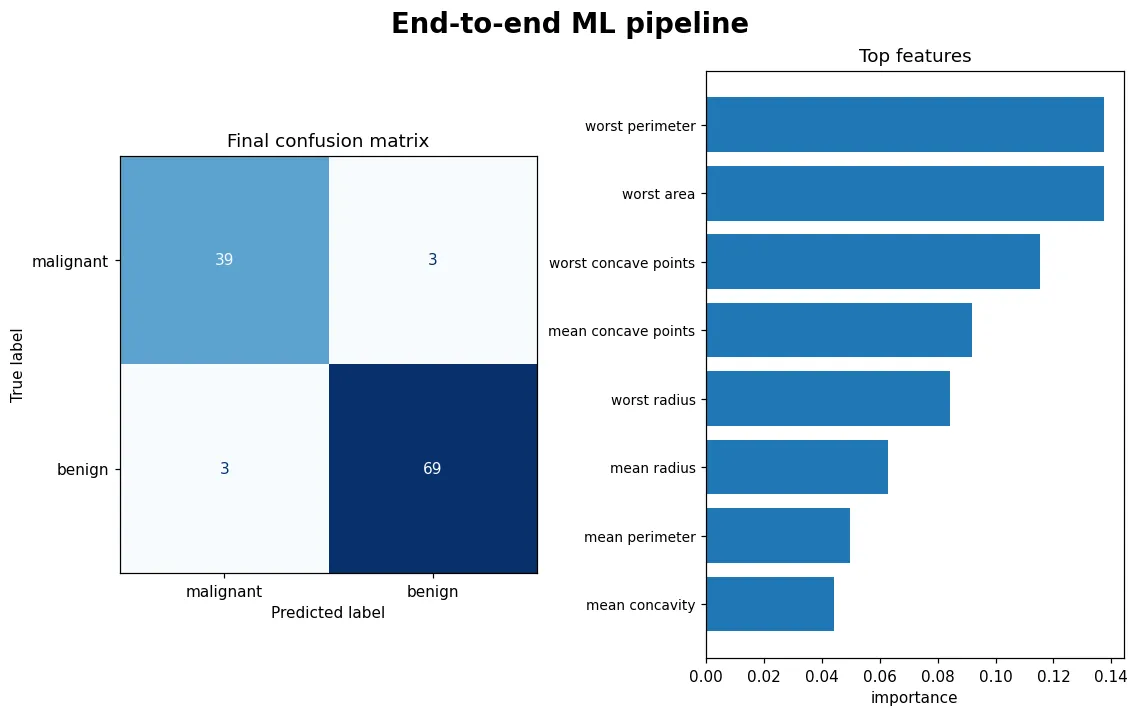
預覽圖就是這條流程的成果:左邊最終混淆矩陣(注意醫療場景中「把惡性誤判成良性」是最危險的錯誤),右邊模型最看重的特徵。
👉 在 Colab 裡把
RandomForestClassifier換成LogisticRegression,整條流程不動就能比較模型——最後挑戰用你自己的 CSV 套同一套六步流程。
#scikit-learn
#pipeline
#gridsearch
#end-to-end
#workflow
留言 0
留言載入中…