07 進階
樹模型與特徵重要性
決策樹用是非題做判斷,人看得懂、還告訴你哪些特徵最重要。把很多棵樹合起來投票,就是橫掃表格資料的隨機森林。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
很多強大的模型是黑盒,但樹模型不是——它的每個判斷都看得懂,還會主動告訴你「我最看重哪些特徵」。這份可解釋性,在醫療、金融這類需要交代決策理由的場景特別珍貴。
這堂課你會學到
- 訓練
DecisionTreeClassifier並把整棵樹畫出來 - 觀察
max_depth如何造成過擬合:訓練分數衝高、測試分數卻停滯 - 用
RandomForestClassifier集合多棵樹投票,大幅提升表現 - 讀
feature_importances_,知道模型根據什麼下判斷
不只給答案,還給理由
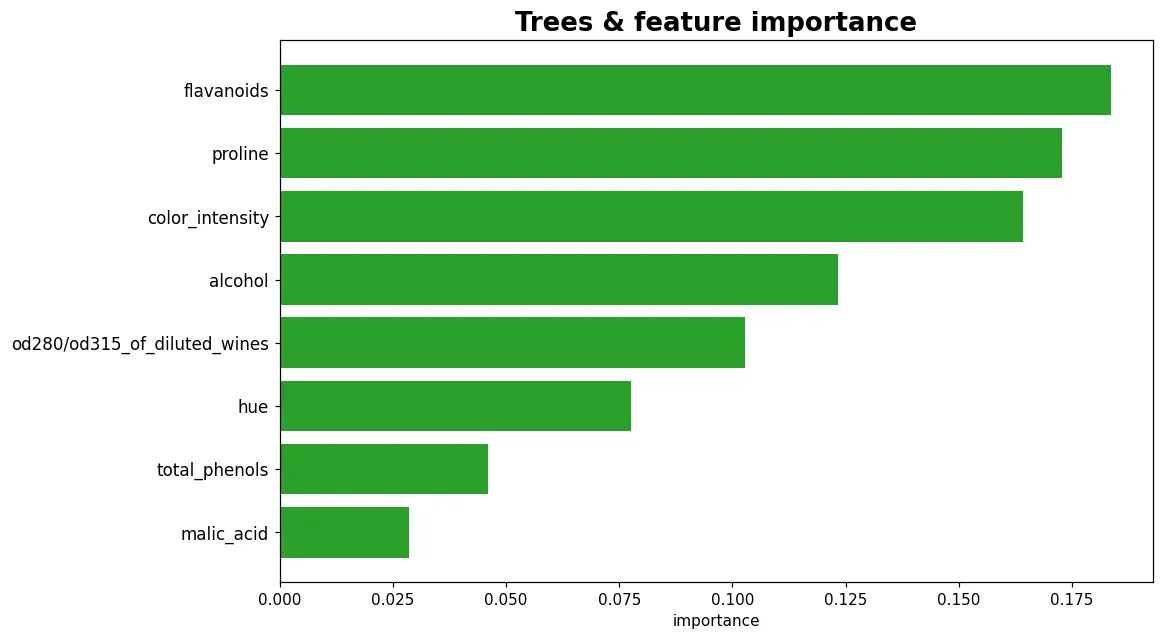
預覽圖是隨機森林算出的特徵重要性——模型不只吐出預測,還排序了「哪些特徵在說話」。這往往是交付成果時最有價值的洞察。
決策樹單獨用容易過擬合、也不穩;隨機森林種很多棵看不同資料子集、不同特徵子集的樹,最後投票,是表格資料的常勝軍。在 notebook 裡你會親眼看到單棵深樹把訓練資料背到 100%、測試卻變差的過擬合曲線。
👉 在 Colab 裡調
n_estimators(50 / 200 / 500),看準確率與訓練時間的取捨;再比較森林和單棵深樹的特徵重要性排序。
#scikit-learn
#decision-tree
#random-forest
#feature-importance
#overfitting
留言 0
留言載入中…