🛠️ 從零打造迷你 GPT
tokenization、自注意力、Transformer、訓練、KV cache,到 SFT 與 DPO 對齊
 01 入門
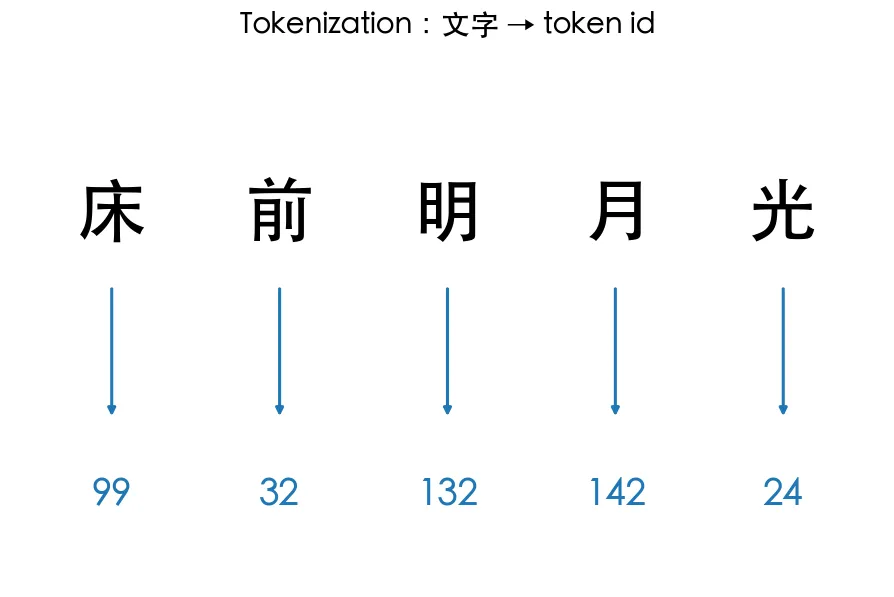
01 入門 斷詞 Tokenization
電腦只看得懂數字。Tokenization 把文字切成 token、再對應成數字——所有 LLM 的入口。從字元級到 BPE。
 02 入門
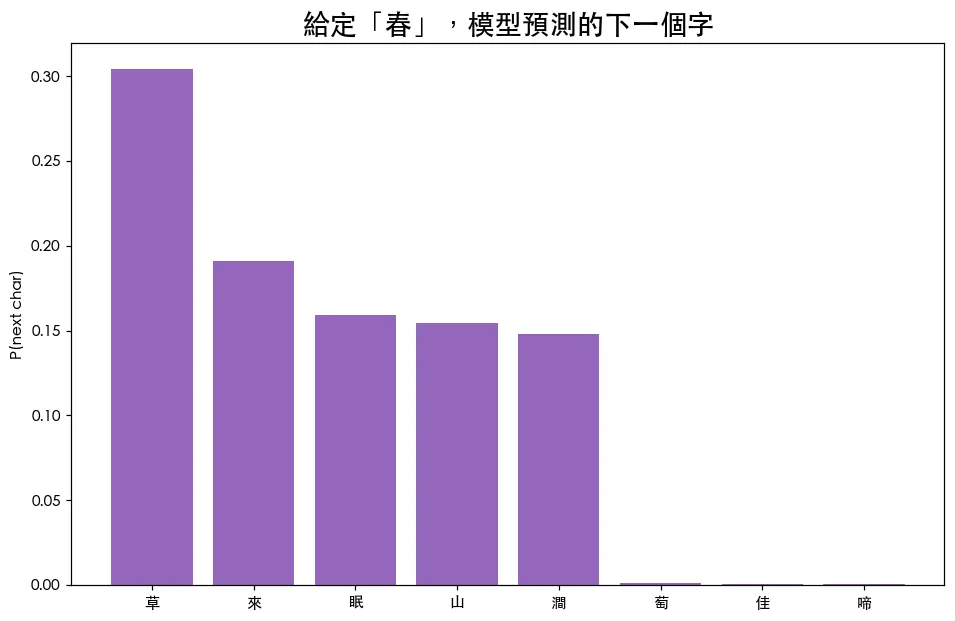
02 入門 預測下一個字
LLM 的本質出乎意料地單純:看著前面的文字,預測下一個字。建立這個框架,並訓練一個最陽春的 bigram 基線。
 03 進階
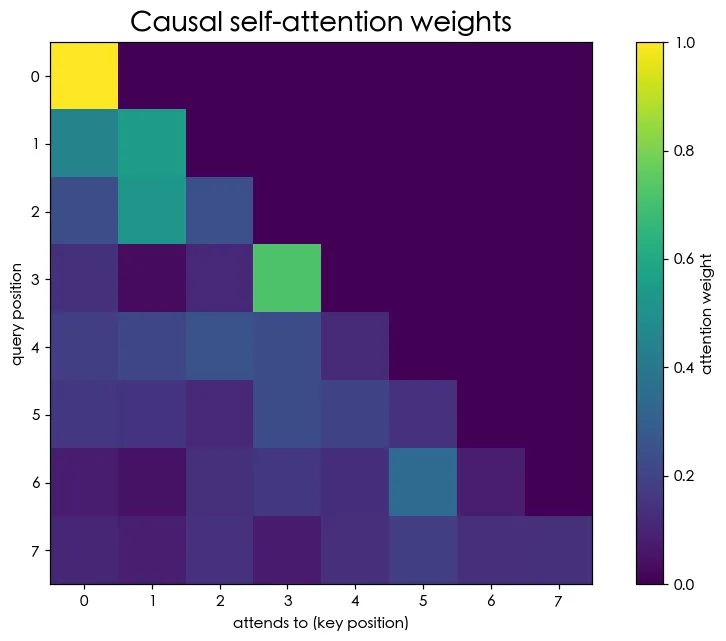
03 進階 自注意力 Self-Attention
Transformer 的心臟。讓每個位置回頭看前面所有字、自己決定該注意誰。從零實作 Q/K/V 與因果遮罩。
 04 進階
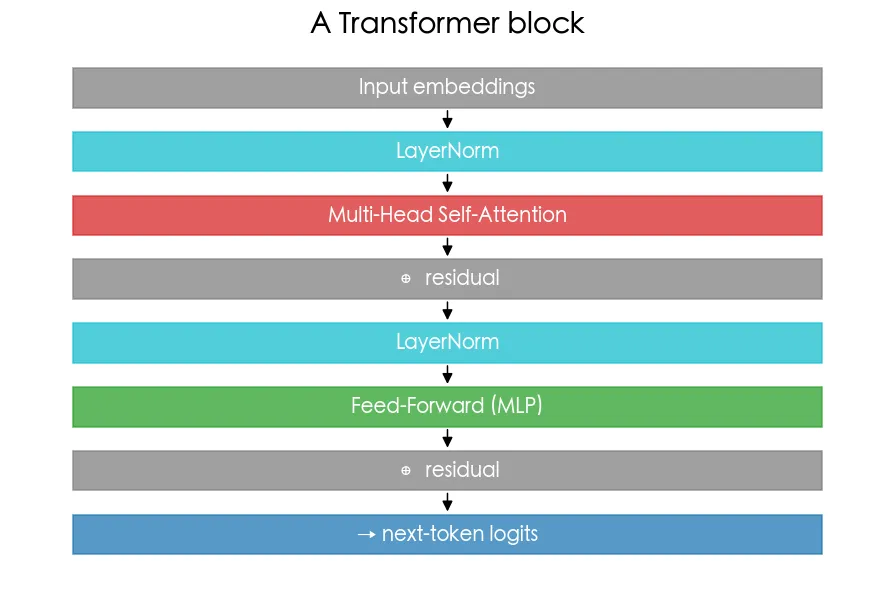
04 進階 組裝 Transformer
把自注意力和其他零件組裝成完整 GPT:多頭注意力、前饋層、殘差連接、LayerNorm,堆成 Transformer block。
 05 進階
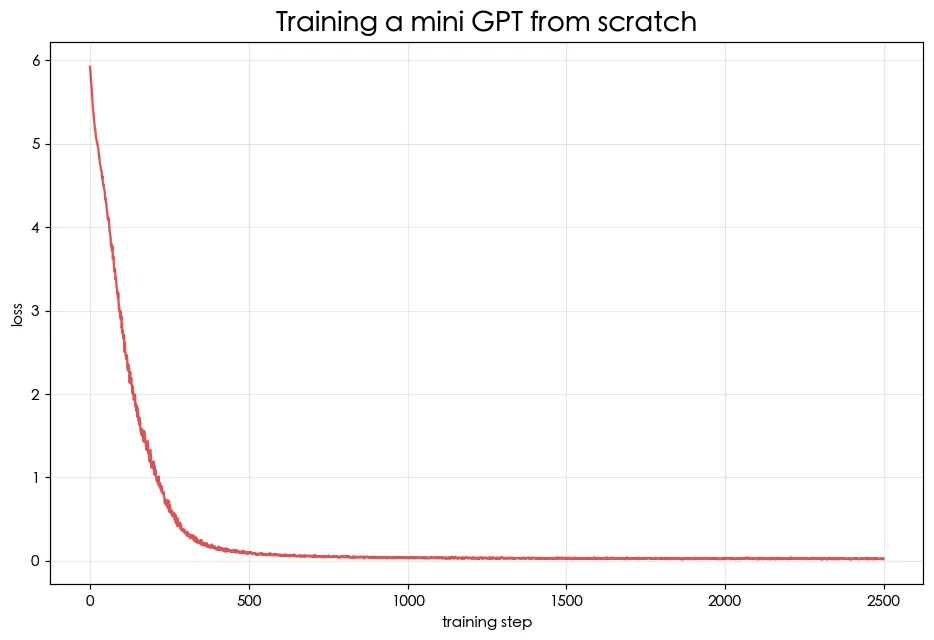
05 進階 訓練你的迷你 GPT
把語料餵進 MiniGPT,真正訓練它,然後讓它接字。你會親眼看到它從亂碼進步到像那麼回事的中文。
 06 進階
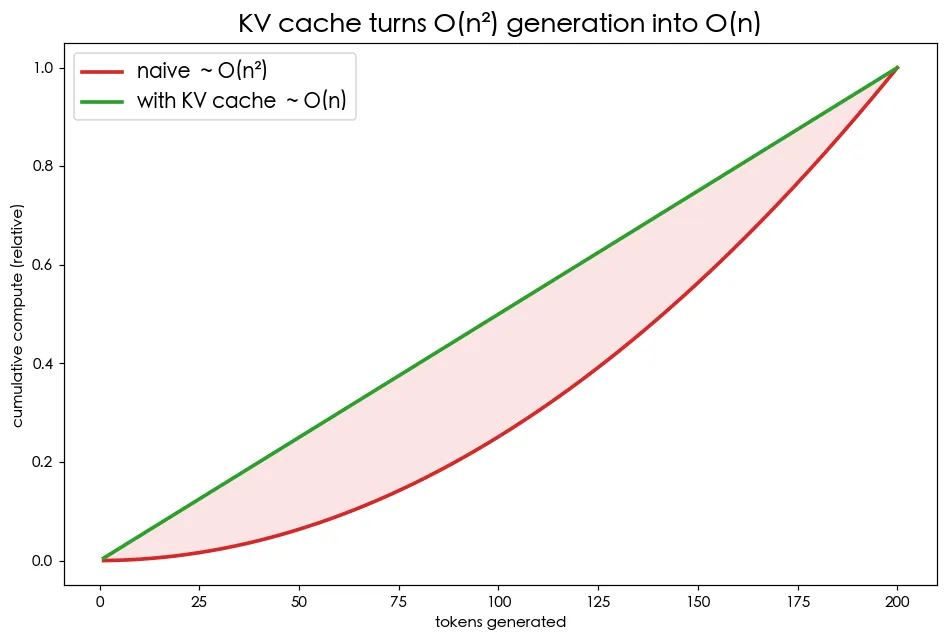
06 進階 生成與 KV Cache
每生成一個字,前面的字都被重算一遍——LLM 推論最大的浪費。KV cache 把算過的 Key/Value 存起來重用,是即時回應的關鍵。
 07 專題
07 專題 對齊 ①:SFT 監督式微調
從『只會接字』到『會照指令回答』。用一堆指令→理想回應的配對繼續訓練模型——對齊的第一步。
 08 專題
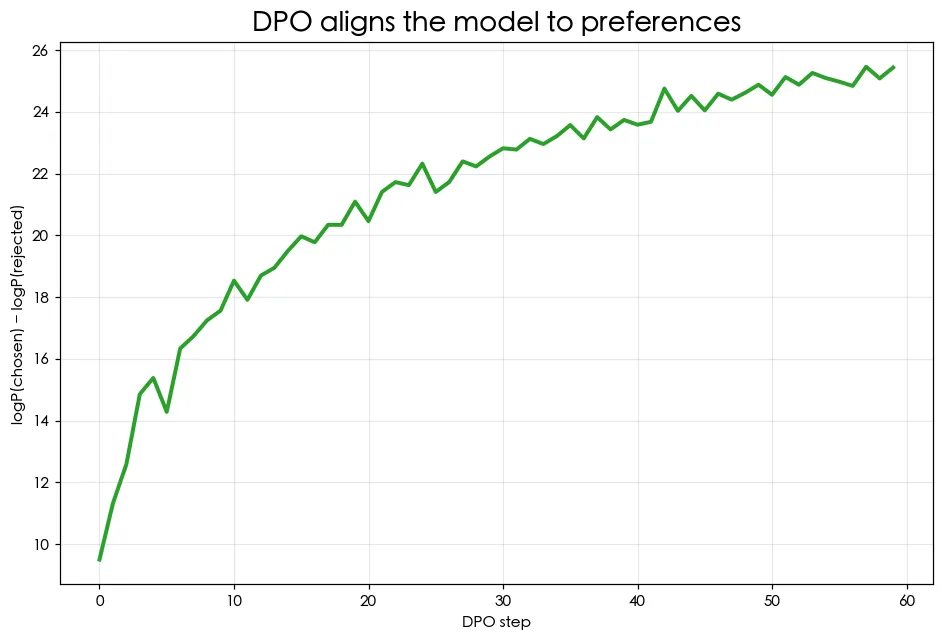
08 專題 對齊 ②:RLHF 與 DPO
讓輸出對齊人類偏好,靠的是 RLHF——ChatGPT 的祕方。講清楚 RLHF 概念,並親手實作它的精簡替代品 DPO。整條學習線的終點。
留言 0
留言載入中…