05 進階
訓練你的迷你 GPT
把語料餵進 MiniGPT,真正訓練它,然後讓它接字。你會親眼看到它從亂碼進步到像那麼回事的中文。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
零件都備齊了——這堂課把語料餵進第 04 課的 MiniGPT,真正訓練它,然後讓它生成文字。雖然模型很小、語料很少,但你會親眼看到它從亂碼進步到「像那麼回事的中文」。
這堂課你會學到
- 寫出 GPT 的訓練迴圈(取 batch → 算 loss → 更新)
- 訓練迷你 GPT,看 loss 下降
- 讓它接字,從一個開頭續寫出唐詩風格的句子
親手訓練出一個會接字的模型
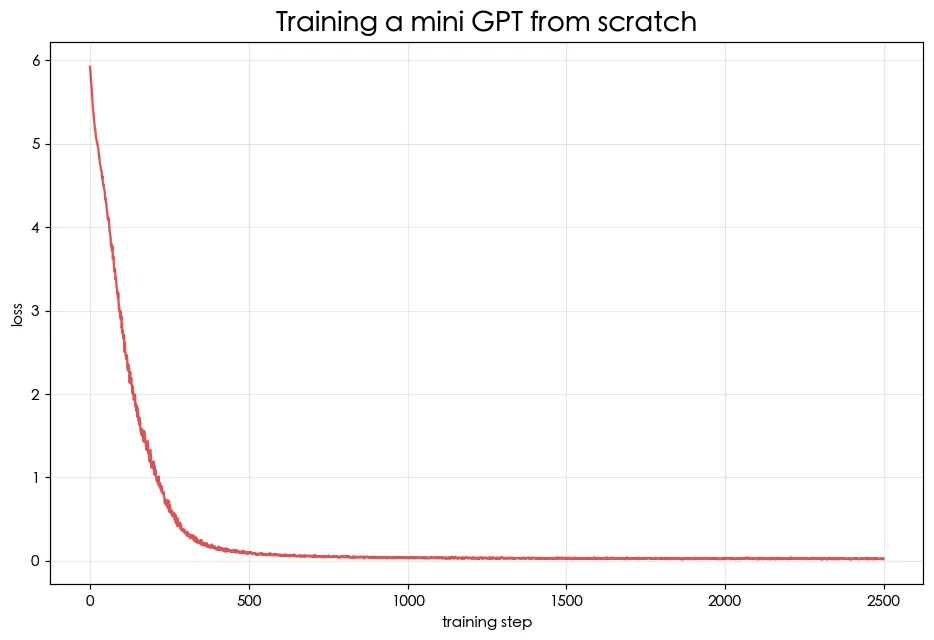
訓練迴圈跟 ml/pytorch 的第一個神經網路一模一樣,只是模型換成 GPT。預覽圖就是 loss 一路下降——模型越來越會預測下一個字。
訓練完給它一個開頭「春」,它會一個字一個字續寫,生出有唐詩韻味的句子。比起第 02 課的 bigram 明顯更連貫,因為自注意力讓它記得住前文。它當然還是會胡謅(模型和語料都極小),但**「從零訓練出一個會接字的語言模型」這件事,你已經親手做到了**。
⚠️ 一開始生成全是重複亂碼——架構沒錯
訓練初期讓它接字,很可能吐出「的的的的」或一團重複的字,讓人懷疑模型是不是寫壞了。
沒壞。模型和語料都極小,訓練初期它只學會了「哪些字最常出現」,於是拼命複讀高頻字——這是語言模型的必經階段,不是 bug。隨著 loss 下降,重複會慢慢被前後文打破,生成才開始有結構。如果訓練夠久還是滿屏複讀,通常是步數不夠、學習率不對或語料太少,而不是 Transformer 架構的問題。
👉 在 Colab(建議開 GPU)裡把
temperature調到 0.3 和 1.2,看生成風格從保守變放飛;或把層數與訓練步數加大,看輸出有沒有變通順。
#llm
#training
#gpt
#text-generation
留言 0
留言載入中…