06 進階
生成與 KV Cache
每生成一個字,前面的字都被重算一遍——LLM 推論最大的浪費。KV cache 把算過的 Key/Value 存起來重用,是即時回應的關鍵。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
每次生成一個字,前面的字其實被重算了一遍又一遍——這是 LLM 推論最大的浪費。KV cache 把算過的 Key/Value 存起來重複利用,是讓 ChatGPT 能即時回應的關鍵工程。這堂課親手實作它。
這堂課你會學到
- 理解自回歸生成為什麼重複計算
- 親手實作 KV cache:只算新 token 的 K/V,舊的存起來重用
- 驗證「有 cache」與「沒 cache」輸出完全相同、但 cache 更快
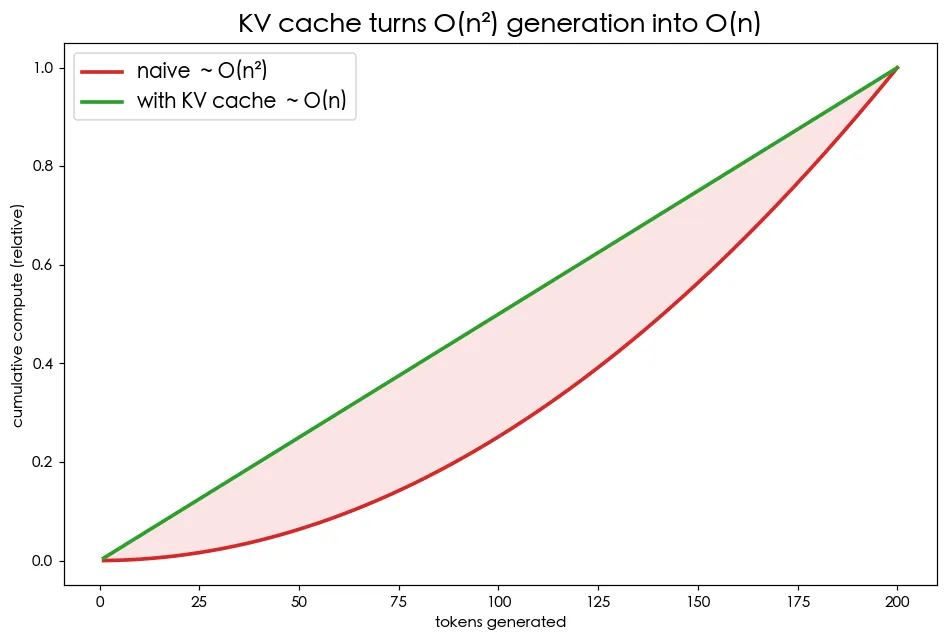
把 O(n²) 變成 O(n)
naive 生成每產一個字,就把整段序列重跑一次,前面字的 Key/Value 一再重算。KV cache 的點子:把每層算過的 K、V 存起來,下一步只算新 token 的 Q/K/V,再接上快取即可。
預覽圖說明了差別:naive 的累積成本隨長度平方成長,cached 接近線性。在 notebook 裡我們親手驗證:兩種方法輸出一字不差(證明 cache 正確),但 cached 明顯更快(實測約 3 倍,序列越長差距越大)。代價是記憶體——cache 要存每層每個 token 的 K、V,這也是長對話越聊越吃 VRAM 的原因。
👉 在 Colab 裡把生成長度從 200 加到 500,看加速比怎麼變,並想想為什麼長對話越聊越吃記憶體。
#llm
#kv-cache
#inference
#optimization
留言 0
留言載入中…