🌲 梯度提升與集成學習
XGBoost、LightGBM、early stopping、調參與 SHAP 解釋——表格資料競賽的王者
 01 入門
01 入門 從單棵樹到集成
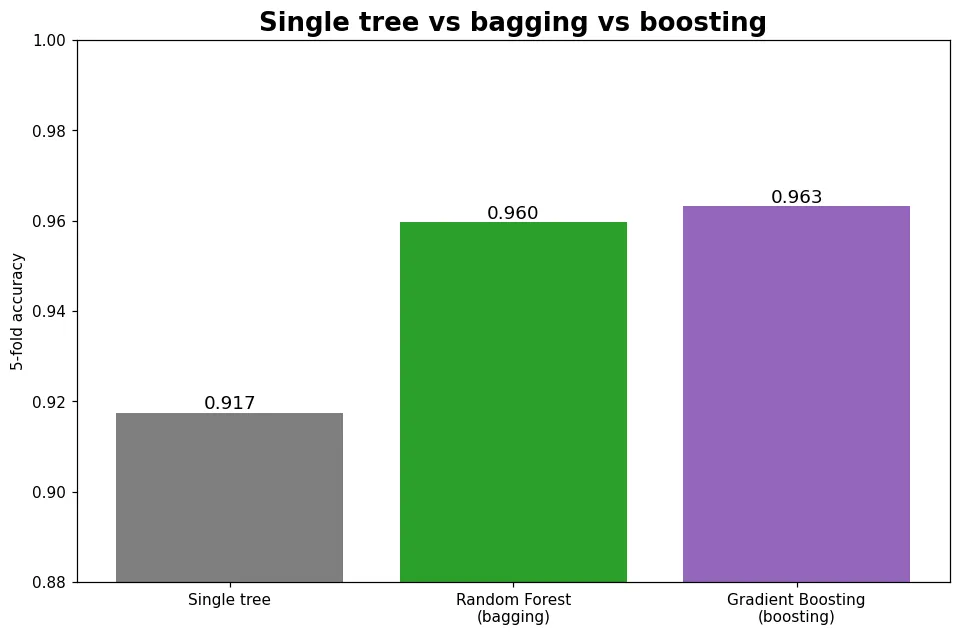
單棵決策樹容易過擬合,集成卻能又穩又準。搞懂兩大門派——bagging(並行投票)與 boosting(逐步糾錯),後者正是 XGBoost 的核心。
 02 入門
02 入門 梯度提升的直覺:逐步糾錯
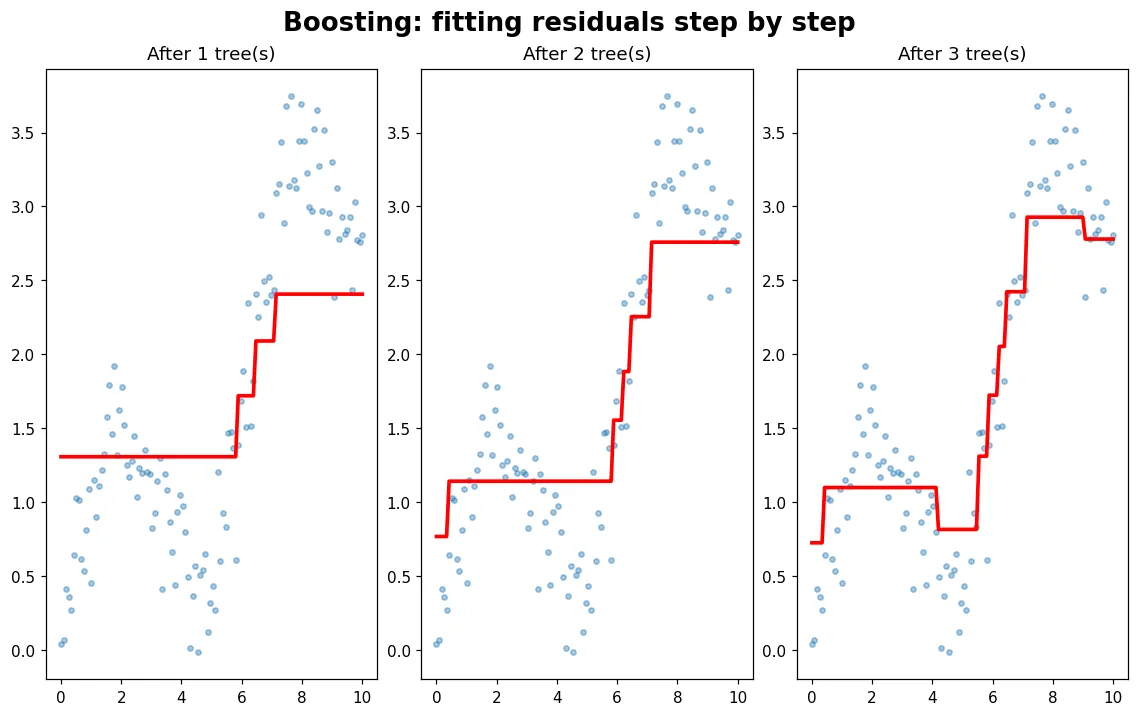
「梯度提升」聽起來嚇人,核心其實一句話:每棵新樹專門擬合前面還沒修好的『殘差』。用一維迴歸把這過程一輪一輪畫給你看。
 03 進階
03 進階 XGBoost 上手
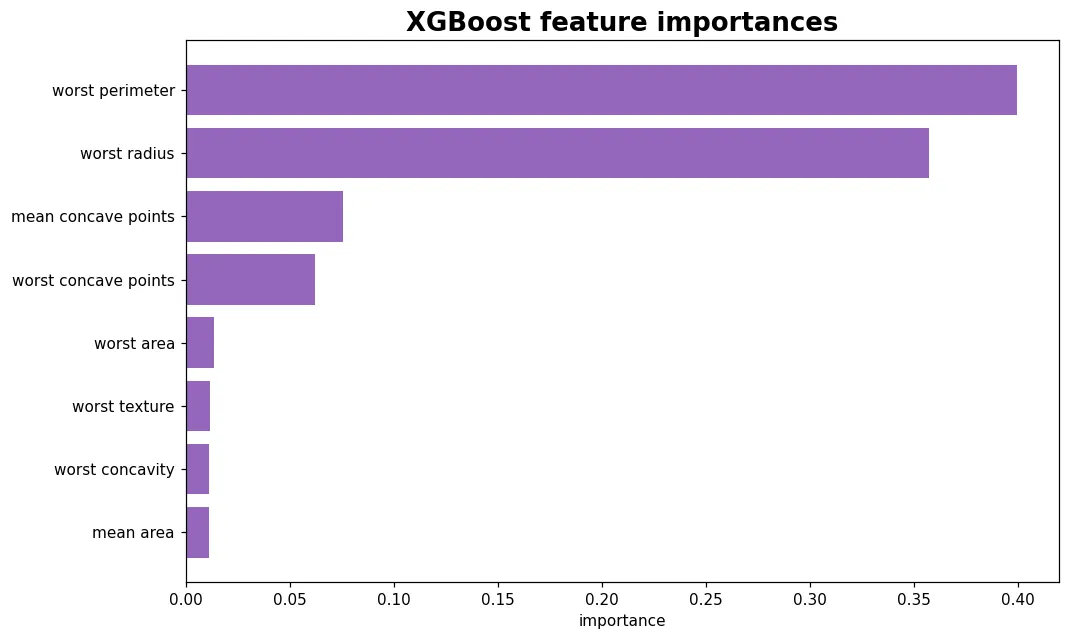
sklearn 的梯度提升概念清楚但慢。工業界與 Kaggle 真正在用的是 XGBoost——更快、內建正則化、會自己處理缺值。跑出你的第一個 XGBoost 模型。
 04 進階
04 進階 過擬合控制與 early stopping
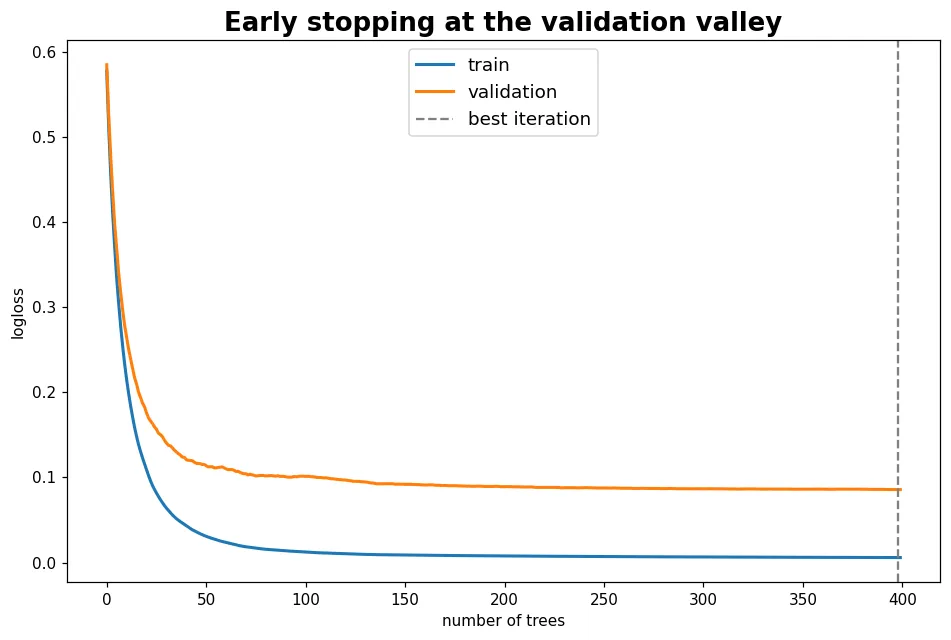
樹種太少會欠擬合、太多會過擬合。early stopping 讓 XGBoost 自己盯著驗證集,一旦不再進步就停在最佳點。
 05 進階
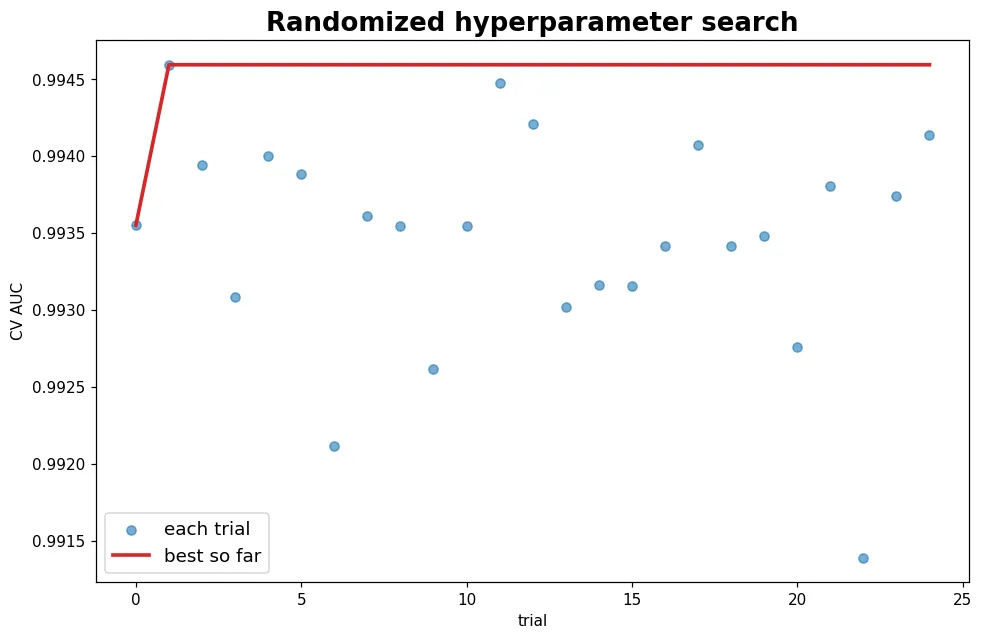
05 進階 超參數調校
XGBoost 有一大把旋鈕,手動試不完。用隨機搜尋系統性地找好設定,並認識更聰明的貝氏最佳化 Optuna。
 06 進階
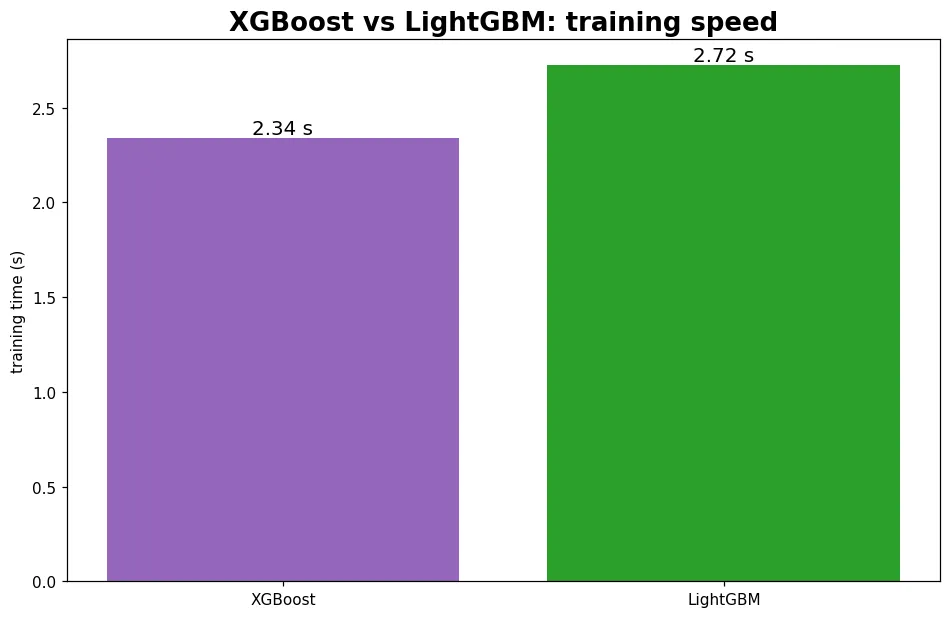
06 進階 LightGBM 與 CatBoost
XGBoost 不是唯一。LightGBM(微軟)以速度著稱,CatBoost(Yandex)擅長類別特徵。比較它們,知道何時用哪個。
 07 進階
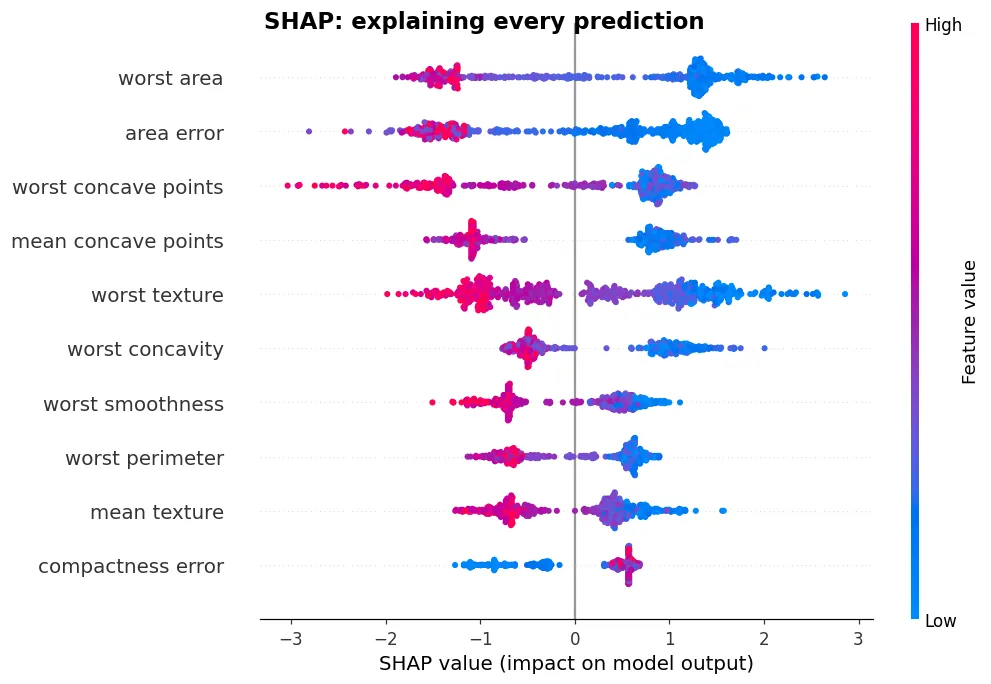
07 進階 SHAP:解釋每一個預測
feature_importances_ 只說得出『整體哪些特徵重要』,說不出方向、也無法解釋單筆預測。SHAP 補上這塊,是模型解釋的黃金標準。
 08 專題
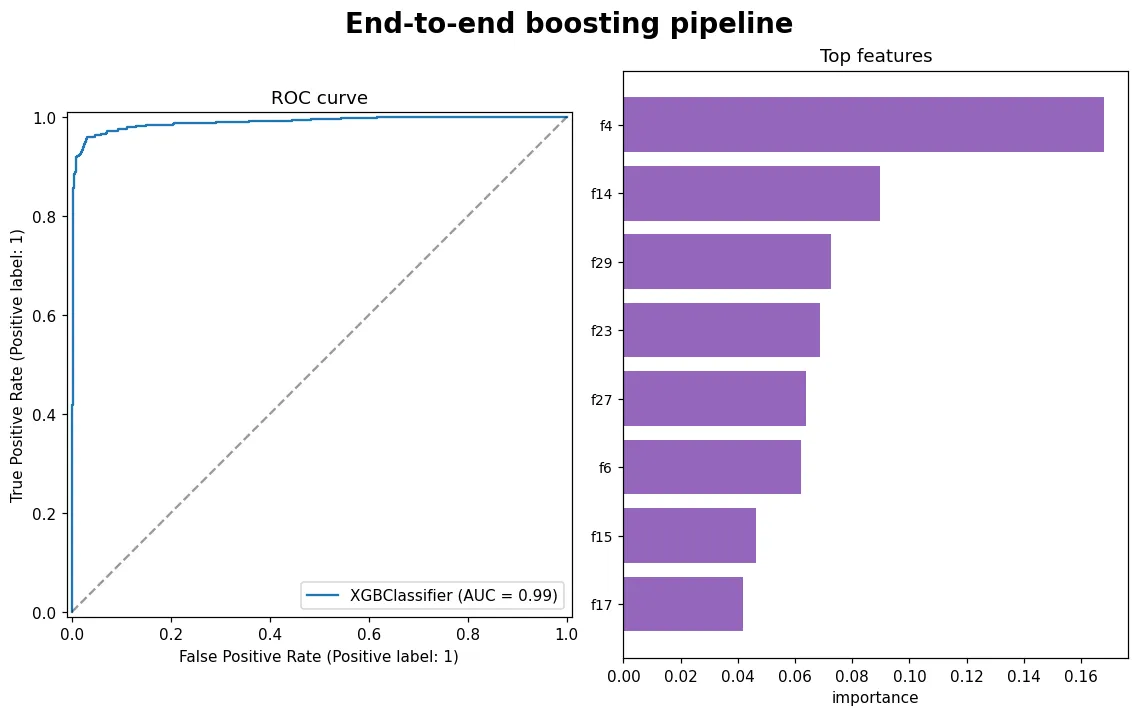
08 專題 實戰:Kaggle 風格完整專案
把前七課全部串起來,走一遍表格資料競賽的標準流程:資料 → 切分 → XGBoost + early stopping → 調參 → 測試集驗收 → SHAP 解讀。
留言 0
留言載入中…