01 入門
從單棵樹到集成
單棵決策樹容易過擬合,集成卻能又穩又準。搞懂兩大門派——bagging(並行投票)與 boosting(逐步糾錯),後者正是 XGBoost 的核心。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
scikit-learn 第 07 課你看過:單一決策樹容易過擬合,而隨機森林種很多棵樹投票,又穩又準。這堂課把「集成學習」的兩大門派講清楚,並點出本模組的主角——boosting。
這堂課你會學到
- 為什麼集成能把一堆弱模型變強
- 分清楚 bagging(並行投票) 與 boosting(逐步糾錯)
- 親手比較單棵樹 / 隨機森林 / 梯度提升的表現
兩種相反的集成思路
| Bagging(隨機森林) | Boosting(梯度提升) | |
|---|---|---|
| 樹怎麼長 | 並行,各自獨立 | 序列,一棵接一棵 |
| 每棵樹看什麼 | 隨機抽的資料子集 | 前面所有樹還沒做好的部分 |
| 在對付什麼 | 降低 variance(過擬合) | 降低 bias(欠擬合) |
| 比喻 | 一群專家各自投票取平均 | 一個學徒不斷修正自己的錯誤 |
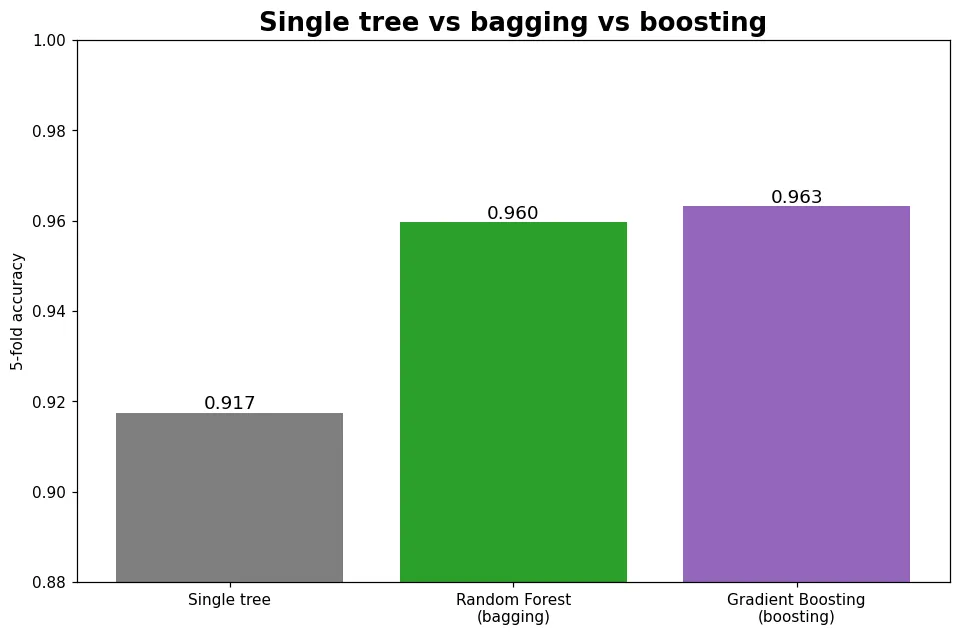
預覽圖就是三者的對決:兩種集成都遠勝單棵樹。但它們「集成」的方式完全相反——bagging 把一堆容易過擬合的深樹平均掉雜訊;boosting 則讓一串很淺的弱樹接力修正彼此的錯誤。本模組專攻後者。
👉 在 Colab 裡把
GradientBoostingClassifier的樹數調大,或換個資料集,看三種模型的排名會不會變。
#ensemble
#bagging
#boosting
#random-forest
留言 0
留言載入中…