02 入門
梯度提升的直覺:逐步糾錯
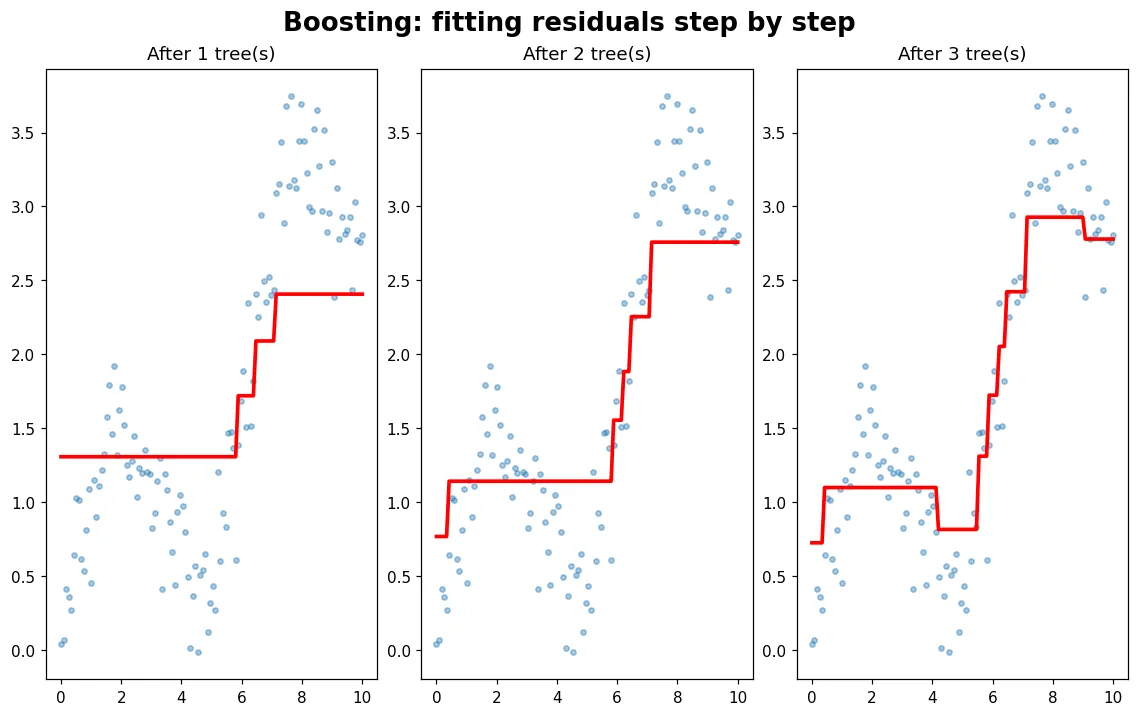
「梯度提升」聽起來嚇人,核心其實一句話:每棵新樹專門擬合前面還沒修好的『殘差』。用一維迴歸把這過程一輪一輪畫給你看。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
「梯度提升」這名字嚇退很多人,但核心其實一句話:每棵新樹,專門去擬合前面所有樹加起來還沒修好的「殘差」。把這句話看懂,XGBoost 就不再是黑魔法。
這堂課你會學到
- 理解 boosting = 不斷擬合殘差
- 親眼看到「加一棵樹、誤差就縮小一點」
- 理解 learning rate(學習率) 在控制什麼
一輪一輪把誤差糾正掉
預覽圖就是核心:先用「全體平均」當最爛的預測,看殘差;種一棵淺樹去擬合殘差、加回去;再看新的殘差……重複。每加一棵淺樹,紅線就更貼合資料一點、誤差就掉一點。
這就是 boosting——一群弱樹,靠接力修正,疊成一個強模型。
而 learning rate 控制每棵樹採納多少修正。學習率小(如 0.1)→ 每步更保守、需要更多棵樹,但通常更不容易過擬合、最終更準。這是 boosting 最重要的旋鈕,後面每一課都會遇到。
👉 在 Colab 裡把學習率改成 0.1 和 1.0,比較三輪後的誤差與紅線的樣子,親手體會這個取捨。
#boosting
#gradient-boosting
#residuals
#learning-rate
留言 0
留言載入中…