03 進階
XGBoost 上手
sklearn 的梯度提升概念清楚但慢。工業界與 Kaggle 真正在用的是 XGBoost——更快、內建正則化、會自己處理缺值。跑出你的第一個 XGBoost 模型。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
sklearn 的 GradientBoosting 適合理解原理,但實戰太慢。工業界與 Kaggle 競賽真正在用的是 XGBoost。好消息:它用的是你早就熟悉的 fit / predict 介面。
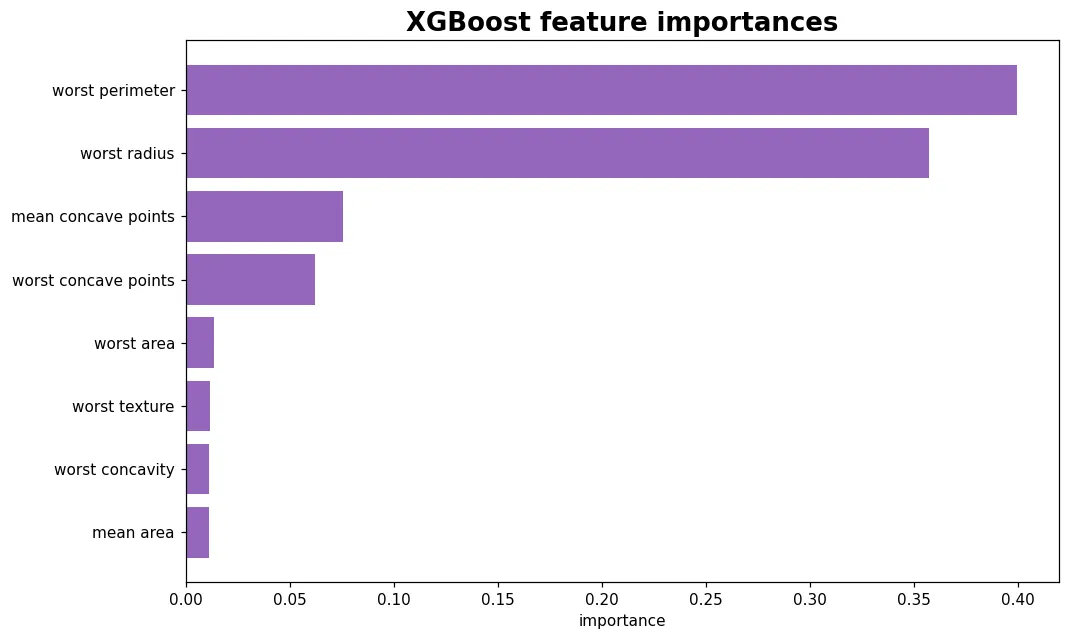
這堂課你會學到
- 用
XGBClassifier(sklearn 風格 API)訓練模型 - XGBoost 相較 sklearn GBDT 的三個賣點
- 最常調的三個參數:
n_estimators/learning_rate/max_depth
XGBoost 強在哪?
- 速度:用了二階梯度資訊與大量工程最佳化,大資料快非常多。
- 正則化:內建 L1/L2(
reg_alpha/reg_lambda)抑制過擬合——sklearn GBDT 沒有。 - 缺值處理:自動學習缺值該往左還是往右走,不用你補值。
三個最常調的參數是一組默契:learning_rate 與 n_estimators 成對(學習率減半,樹大約要加倍),max_depth 控制每棵樹能抓多複雜的交互作用。下一課就專門處理「樹該種幾棵」這個過擬合問題。
👉 在 Colab 裡把
max_depth從 3 改成 8,看訓練準確率與測試準確率分別怎麼變——這是過擬合的現場。
#xgboost
#gradient-boosting
#regularization
留言 0
留言載入中…