04 進階
過擬合控制與 early stopping
樹種太少會欠擬合、太多會過擬合。early stopping 讓 XGBoost 自己盯著驗證集,一旦不再進步就停在最佳點。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
XGBoost 樹種太少會欠擬合、太多會過擬合。手動試到死太累——early stopping 讓模型自己盯著驗證集,一旦連續幾輪不再進步就停。這堂課也順道認識幾個關鍵的正則化旋鈕。
這堂課你會學到
- 用驗證集畫出「訓練 vs 驗證」學習曲線,看見過擬合
- 用
early_stopping_rounds自動挑最佳樹數 - 認識
subsample/colsample_bytree/reg_lambda等正則化參數
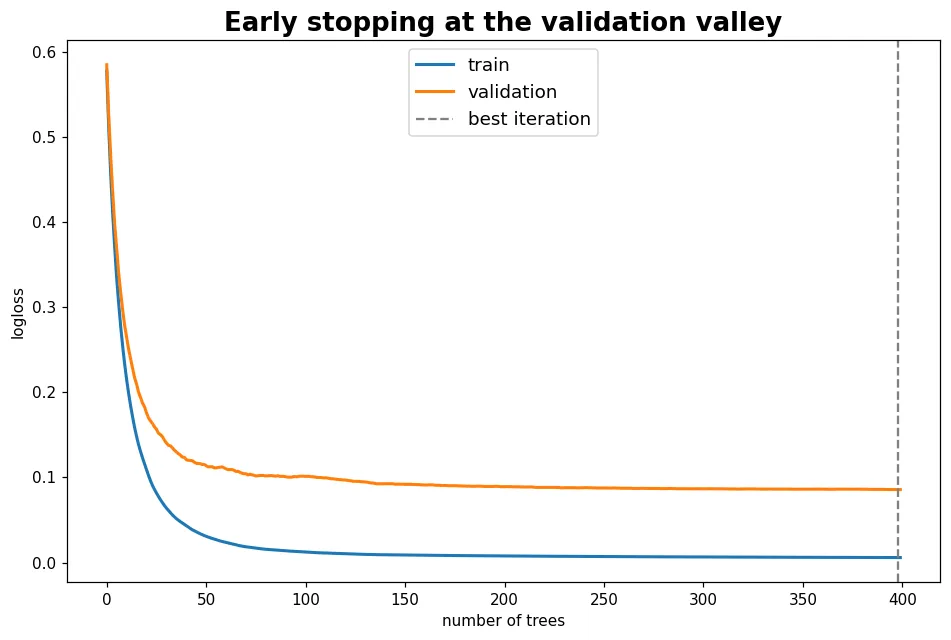
看見過擬合的長相
預覽圖是經典的過擬合曲線:訓練 logloss 一路向下,驗證 logloss 觸底後反彈。兩條線開始分岔的地方,就是模型從「學規律」轉向「背雜訊」的臨界點。
設一個很大的 n_estimators,再給 early_stopping_rounds,XGBoost 就會自動停在驗證的谷底,並用 best_iteration 告訴你最佳樹數。搭配 subsample(每棵樹只用部分資料)、colsample_bytree(只用部分特徵)、reg_lambda(L2 正則化)等旋鈕,能進一步把過擬合壓下去。
👉 在 Colab 裡把
learning_rate調到 0.01,觀察best_iteration會變大還是變小——並想想為什麼。
#xgboost
#early-stopping
#regularization
#overfitting
留言 0
留言載入中…