05 進階
超參數調校
XGBoost 有一大把旋鈕,手動試不完。用隨機搜尋系統性地找好設定,並認識更聰明的貝氏最佳化 Optuna。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
XGBoost 有一大把旋鈕,組合是天文數字,手動試到天荒地老也試不完。這堂課用隨機搜尋系統性地找好設定,並認識 Kaggle 高手的祕密武器 Optuna。
這堂課你會學到
- boosting 該優先調哪些參數
- 用
RandomizedSearchCV在參數空間有效率地搜尋 - grid / random / 貝氏(Optuna)搜尋的差別
調參優先序
learning_rate+n_estimators(一對,配 early stopping)max_depth、min_child_weight(樹的複雜度)subsample、colsample_bytree(隨機性)reg_lambda、reg_alpha(正則化)
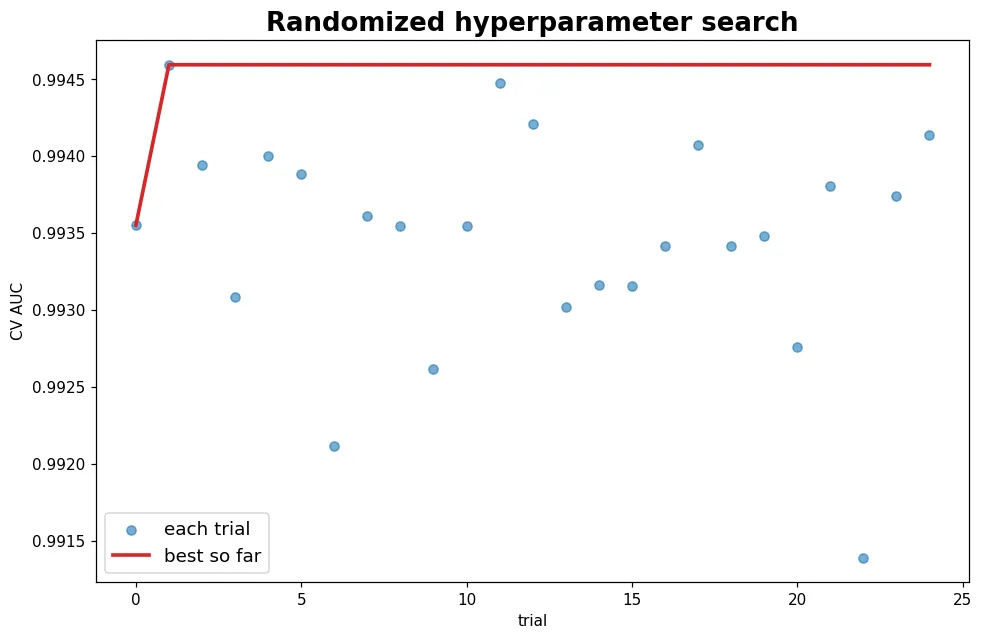
預覽圖顯示隨機搜尋的過程:每個點是一組隨機參數的 CV 分數,紅線是「目前最佳」。用同樣的預算,隨機搜尋通常比 grid search 找到更好的解(因為 grid 會把預算浪費在不重要的維度上)。
更進階的是 Optuna——它用貝氏最佳化,根據已試過的結果聰明地決定下一組要試什麼,用更少嘗試找到更好的參數。本課不展開,但你該知道它存在,在 Colab 裡 pip install optuna 就能玩。
👉 在 Colab 裡把搜尋次數
n_iter加大,看最佳 AUC 有沒有提升,代價是什麼。
#xgboost
#hyperparameter
#randomized-search
#optuna
留言 0
留言載入中…