🔍 資料分析實戰
用 pandas 清理真實資料、EDA 找洞見、seaborn 說故事、特徵工程與統計檢定,最後接 sklearn 做完整分析
 01 入門
01 入門 資料科學的流程 · 從問題到結論
資料科學不只是跑模型——前面的清理與探索才佔大部分時間。這堂課建立完整流程的心智模型,並載入經典的 Titanic 真實資料集,開始回答「什麼樣的乘客比較容易生還」。
 02 入門
02 入門 資料清理 · 髒資料變乾淨
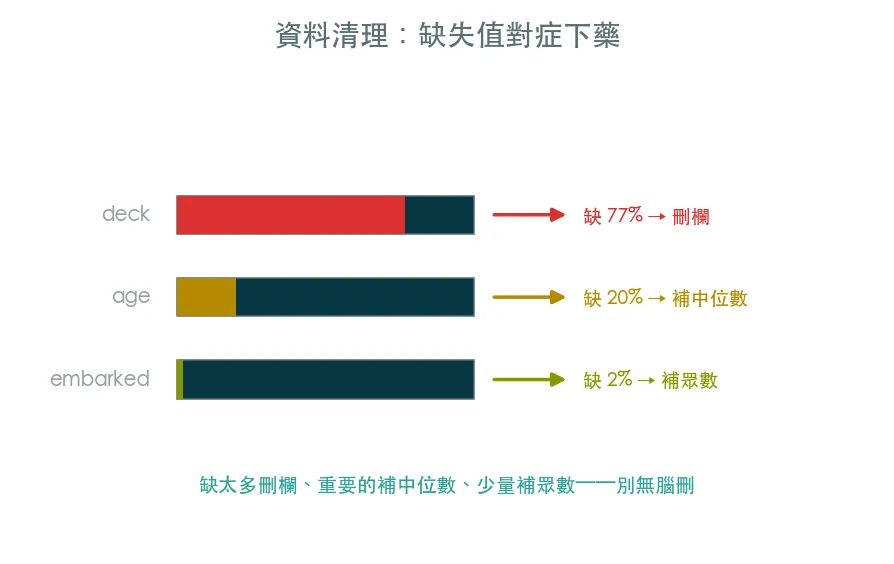
真實資料總是有缺失、型別不對、有重複、有離群值——垃圾進垃圾出。這堂課把 Titanic 清乾淨:找出缺失值、對症下藥(刪欄 vs 補中位數 vs 補眾數)、處理重複與離群。
 03 入門
03 入門 探索式分析 EDA · 讓資料說話
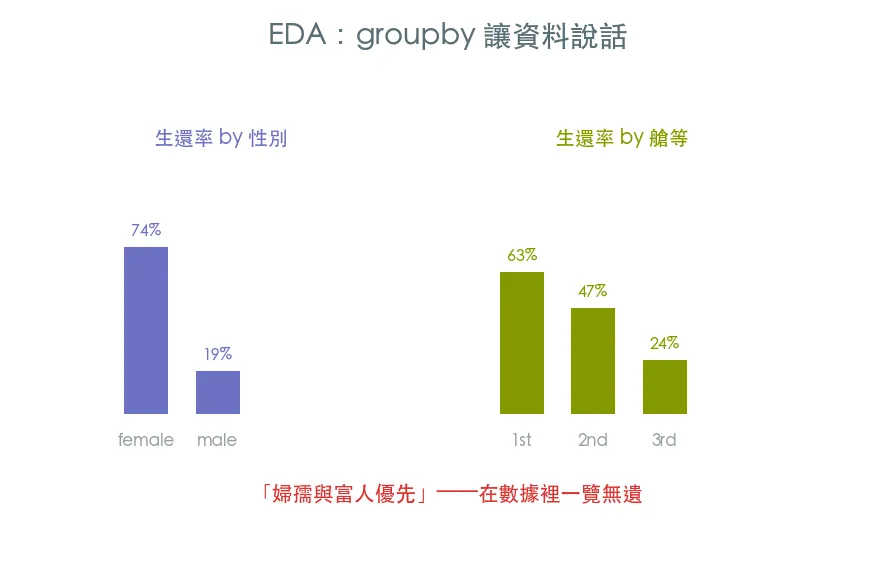
資料乾淨後最有趣的一步:用 groupby、樞紐表、相關係數,在建模前先把資料裡的規律挖出來。回答「什麼樣的乘客比較容易生還」——性別、艙等、票價的故事逐漸浮現。
 04 入門
04 入門 視覺化說故事 · 讓洞見一眼就懂
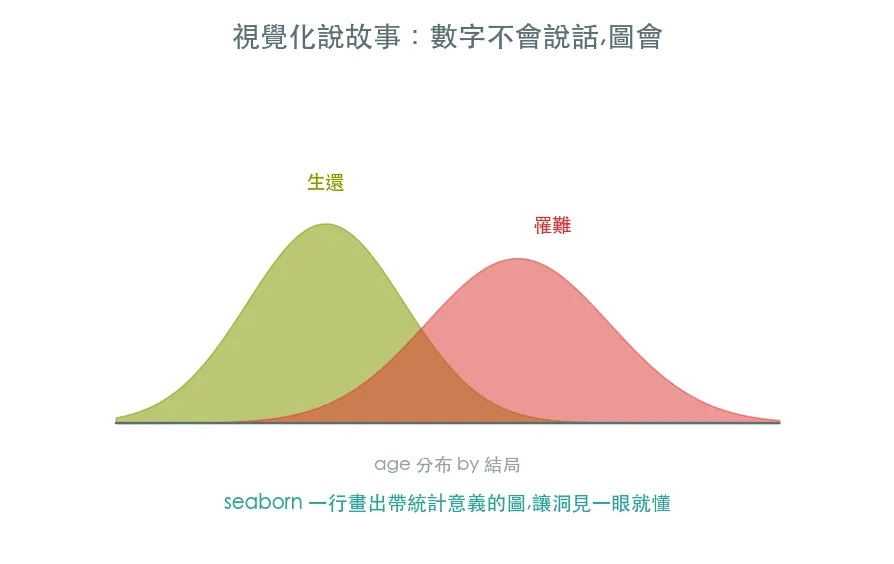
數字不會說故事,圖會。用 seaborn 把 EDA 的發現畫成圖——一行畫出帶統計意義的長條圖、分布圖、相關熱力圖,讓不懂資料的人也一眼看懂誰比較容易生還。
 05 進階
05 進階 特徵工程 · 把原始欄位變成模型的養分
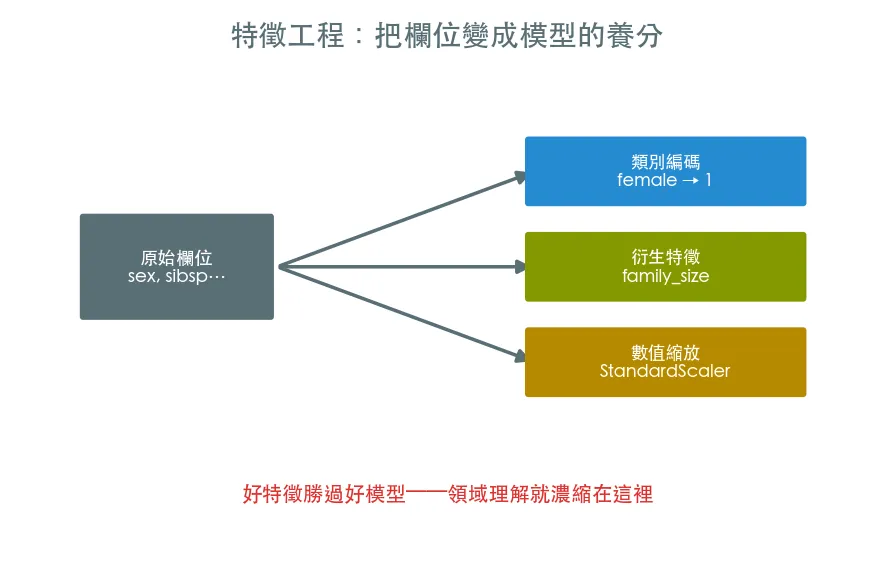
模型不會自己看懂原始資料。特徵工程把欄位加工成模型更好吃的形式——類別編碼、衍生特徵、數值縮放。好特徵常比換更厲害的模型還有效。
 06 進階
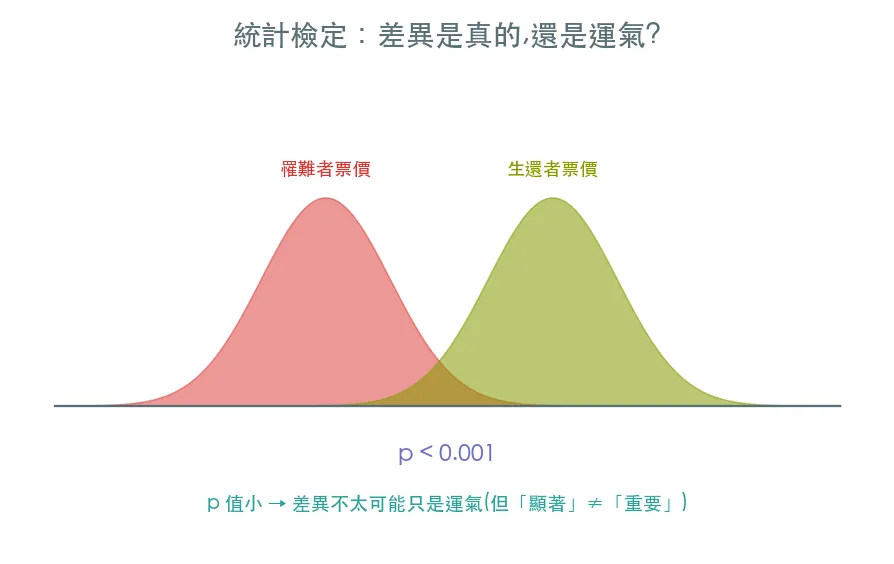
06 進階 統計檢定 · 這個差異是真的,還是運氣?
EDA 看到女性生還率比男性高,但會不會只是抽樣的運氣?假設檢定用 p 值回答這個問題。t 檢定比兩組數值平均、卡方檢定看類別關聯——這也是 A/B test 的數學基礎。
 07 進階
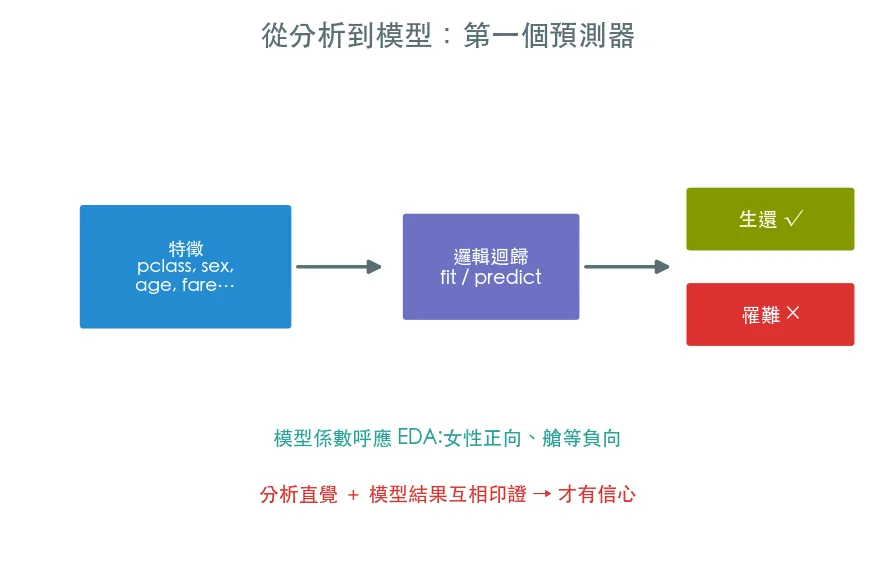
07 進階 從分析到模型 · 第一個預測器
前面六課我們理解了資料:誰容易生還、為什麼。最後把理解變成預測——用清理 + 特徵工程的成果,接上 sklearn 的 fit/predict 建一個 baseline,模型係數還會呼應 EDA 的發現。
 08 專題
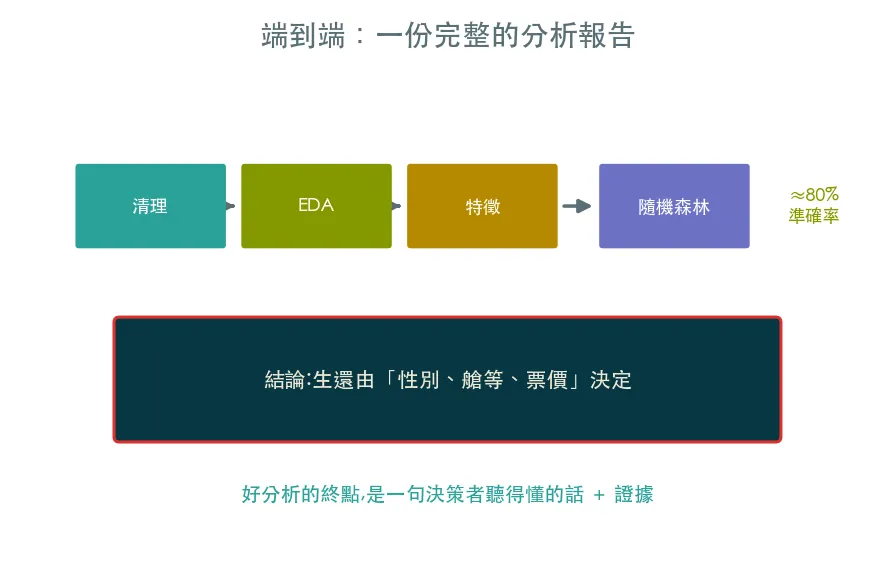
08 專題 端到端實戰 · 一份完整的分析報告
整條軌道的收尾。把問題→資料→清理→EDA→特徵→模型→結論走完整一輪,產出一份能交付的分析:用隨機森林以約八成準確率預測生還,並收斂成一句人話的結論。
留言 0
留言載入中…