05 進階
特徵工程 · 把原始欄位變成模型的養分
模型不會自己看懂原始資料。特徵工程把欄位加工成模型更好吃的形式——類別編碼、衍生特徵、數值縮放。好特徵常比換更厲害的模型還有效。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
模型不會自己「看懂」原始資料。特徵工程就是把原始欄位加工成模型更好吃的形式——這往往比換更厲害的模型還有效。
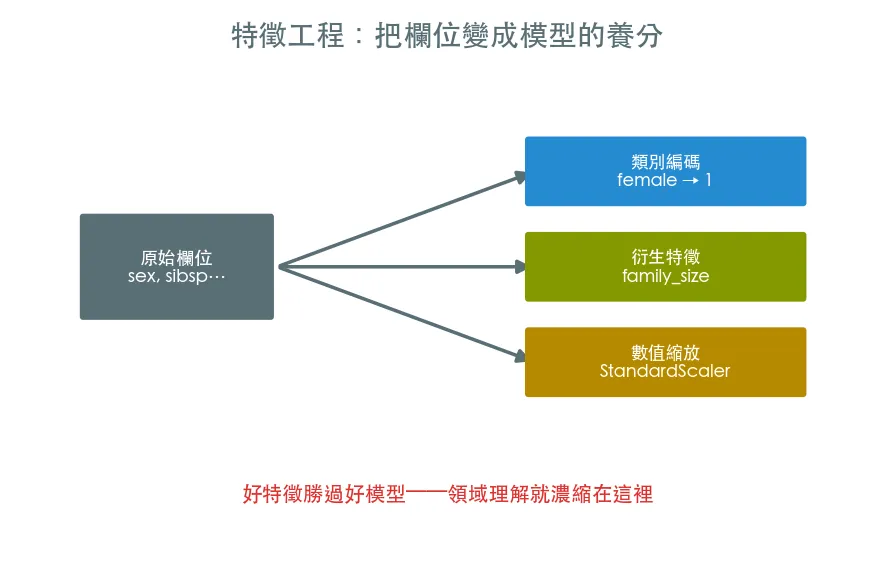
三件最常見的事
- 類別編碼:
sex="female"這種文字模型看不懂,要轉成數字(二元映射 0/1、多類別 one-hot)。- 衍生特徵:從現有欄位算出更有意義的新欄位(例如
家庭人數 = 兄弟姊妹 + 父母子女 + 自己)。- 數值縮放:把不同尺度的數值(age 0–80、fare 0–500)拉到同一基準。
這堂課你會學到
- 用
map做二元編碼、pd.get_dummies做 one-hot - 衍生
family_size與is_alone——抓到原始欄位沒直接表達的訊號(獨自一人生還率明顯較低) - 用
StandardScaler把數值標準化到平均 0、標準差 1 - 體會「好特徵勝過好模型」這句業界金句
為什麼特徵工程這麼重要?
同樣的資料、同樣的模型,特徵做得好不好,結果天差地遠。family_size 這個衍生特徵把「sibsp 和 parch 加起來才有意義」這件模型不會自己想到的事,直接餵給它。資料科學家對問題的領域理解,就濃縮在特徵工程裡——這是再強的 AutoML 也難以完全取代的人類價值。
💡 進階特徵還能從
name抽出頭銜(Mr/Mrs/Master)、把 age 分箱成兒童/成人/老人。每一個都是「把領域知識編碼成數字」。下一課,我們用統計檢定確認這些差異是真的、不是運氣。
#data-science
#feature-engineering
#encoding
#scaling
留言 0
留言載入中…