統計檢定 · 這個差異是真的,還是運氣?
EDA 看到女性生還率比男性高,但會不會只是抽樣的運氣?假設檢定用 p 值回答這個問題。t 檢定比兩組數值平均、卡方檢定看類別關聯——這也是 A/B test 的數學基礎。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
EDA 看到「女性生還率比男性高」,但這會不會只是抽樣的運氣?統計檢定就是用來回答這個問題的。
核心:假設檢定與 p 值
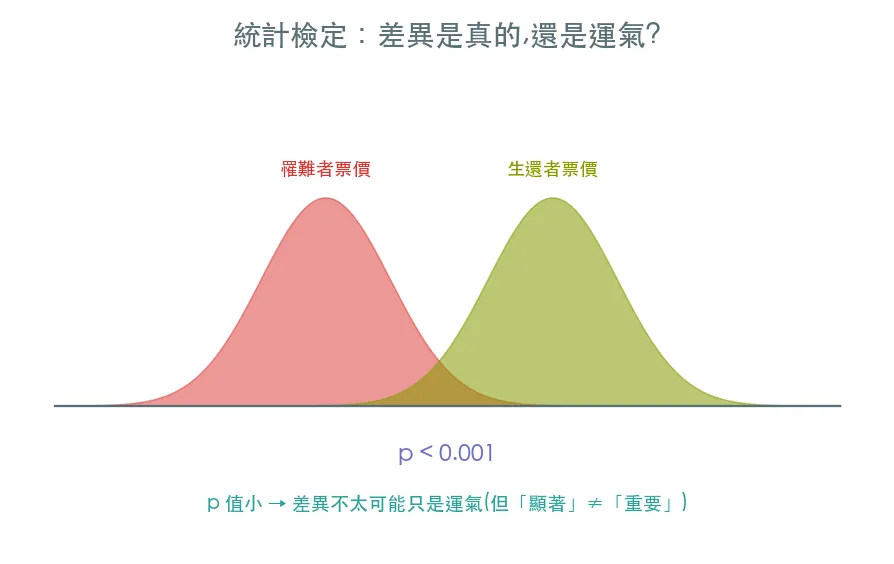
假設檢定先假設「其實沒差」(虛無假設),再算出「如果真的沒差、卻看到這麼大的差異」的機率——這就是 p 值。p 值很小(慣例 < 0.05),就有信心說「差異是真的」。
這也是 A/B test 的數學基礎:網站改版有沒有真的提升轉換率,用的就是同一套邏輯。
這堂課你會學到
- t 檢定:比較兩組數值的平均(生還者 vs 罹難者的票價有差嗎?)
- 卡方檢定:看兩個類別變數有沒有關聯(性別 vs 生還)
- 怎麼讀 p 值:小 = 「不太可能只是運氣」
- 一個關鍵心態:統計顯著 ≠ 實務重要
最容易被誤解的一點
p 值小,只代表「差異不太可能只是運氣」,不等於「差異很大」或「很重要」。樣本一大,再小的差異 p 值也會很小。所以好的分析會同時報告 p 值(有沒有差)與效果大小(差多少)——只看 p 值下結論,是資料分析最常見的陷阱之一。
⚠️ p 值 > 0.05,不等於「兩組一樣」
反方向的誤讀更常見:檢定算出 p = 0.3,就下結論「兩組沒有差異」。這是錯的。
p 值大,只代表「目前的資料不足以證明有差異」,不是「證明了沒差異」。可能真的沒差,也可能只是樣本太少、雜訊太大,沒能檢出本來就存在的差異。「沒有證據說不一樣」和「有證據說一樣」是兩件完全不同的事——把前者當成後者,是 A/B test 最常見的誤判(常害人提早喊停一個其實有效的實驗)。
為什麼工程師也要懂這個
A/B test 是產品迭代的標配:新功能到底有沒有用,不能靠「感覺」,要靠檢定。懂假設檢定,你才不會把「兩天的數據漲了一點」當成功勞,也才能設計出可信的實驗。這是資料驅動決策的底層素養。
💡 進階主題:多重比較校正(同時測很多假設時 p 值要更嚴格)、效果量(Cohen’s d)、信賴區間。但先把「p 值在回答什麼」這件事搞懂,就贏過很多人了。下一課,把分析收斂成一個預測模型。
留言 0
留言載入中…