07 進階
從分析到模型 · 第一個預測器
前面六課我們理解了資料:誰容易生還、為什麼。最後把理解變成預測——用清理 + 特徵工程的成果,接上 sklearn 的 fit/predict 建一個 baseline,模型係數還會呼應 EDA 的發現。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
前面六課我們理解了資料:誰容易生還、為什麼。最後一步,把理解變成預測——訓練一個模型,輸入乘客資料、輸出「會不會生還」。
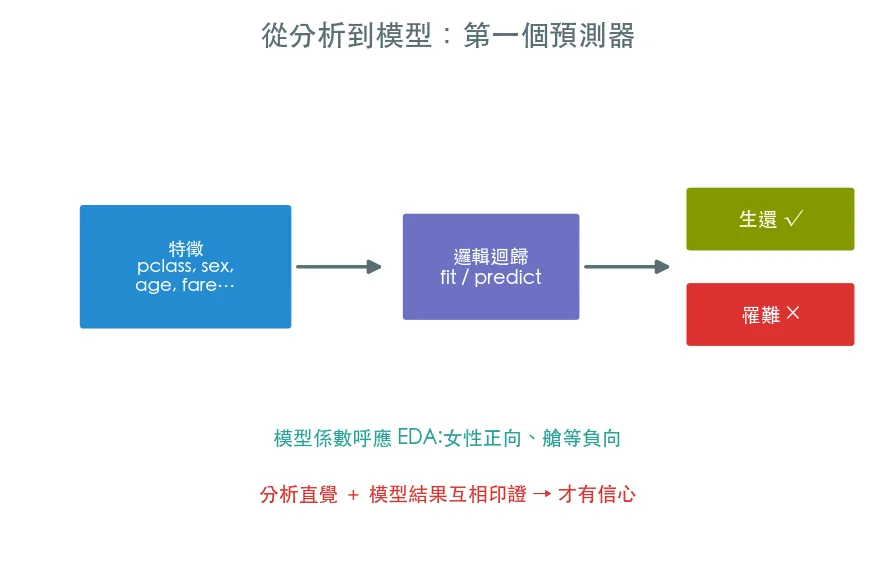
這課是資料科學與機器學習的交接點:用前面清理 + 特徵工程的成果,接上 ml/scikit-learn 教過的 fit / predict,建一個 baseline。
這堂課你會學到
- 把前幾課的清理 + 編碼 + 衍生特徵濃縮成建模用的特徵矩陣
- 用
train_test_split切訓練/測試集——評估對沒看過的人準不準 - 訓練邏輯迴歸 baseline,跟「全猜死」的基準準確率比
- 看模型係數:它學到的東西,呼應你 EDA 的發現
分析與建模互相印證
最漂亮的時刻在這課末尾:邏輯迴歸的係數顯示 sex(女性)強烈正向、pclass(艙等)負向——模型自己「學到」了你前面用 EDA 看到的故事。當分析直覺與模型結果互相印證,你才真正有信心:這不是巧合,是真實的規律。
baseline 的價值
第一個模型不該追求最高分,而是建立一個誠實的參考點:準確率要跟「最笨的猜法」(全猜多數類)比,才知道模型有沒有真本事。有了 baseline,後續任何改進(換模型、調參、加特徵)才有對照,才知道值不值得。
👉 想讓模型更準?這正是
ml/scikit-learn軌道的主場:換樹模型/梯度提升、交叉驗證、調參、Pipeline。這條資料科學軌道幫你把「資料準備好、理解透」,模型的深水區交給 ML 軌道。下一課壓軸,把整條流程串成一份完整報告。
#data-science
#scikit-learn
#logistic-regression
#modeling
留言 0
留言載入中…