08 專題
端到端實戰 · 一份完整的分析報告
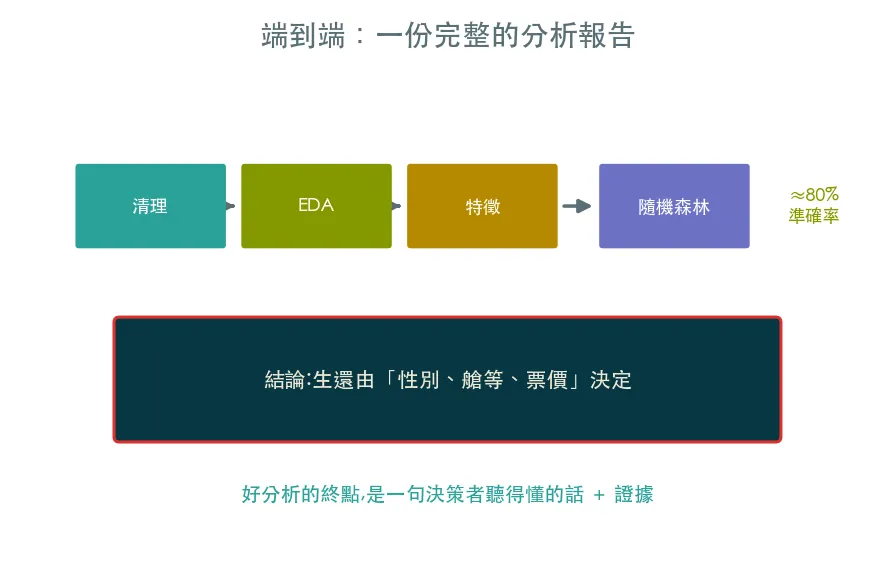
整條軌道的收尾。把問題→資料→清理→EDA→特徵→模型→結論走完整一輪,產出一份能交付的分析:用隨機森林以約八成準確率預測生還,並收斂成一句人話的結論。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
整條軌道的收尾。把問題 → 資料 → 清理 → EDA → 特徵 → 模型 → 結論走完整一輪,產出一份能交付的分析。這正是資料科學家的日常產出長相。
這堂課你會做完整一輪
問題:什麼樣的鐵達尼號乘客比較容易生還?能不能預測?
- 取得與清理:載入、補缺值、刪冗欄
- 關鍵發現:EDA 濃縮成幾個生還率對比
- 特徵工程 + 建模:編碼、衍生、用隨機森林訓練
- 評估:準確率 + 完整的 classification report
- 特徵重要度:哪些因素最關鍵
- 結論:收斂成一句人話 + 支撐它的證據
一份分析的終點是「一句結論」
鐵達尼號的生還,主要由「性別、艙等、票價」決定:女性與高艙等乘客生還率遠高於平均。用這幾個特徵,隨機森林能以約八成準確率預測一位乘客是否生還。
技術做得再花俏,最後都要回到一句決策者聽得懂的話,加上支撐它的圖表、檢定與模型。能把資料變成這句話,你就完成了資料科學最核心的價值轉換。
軌道小結
你走完了資料科學的完整流程:
- 流程與載入(01)→ 清理(02)→ EDA(03)→ 視覺化(04)
- 特徵工程(05)→ 統計檢定(06)→ 建模(07)→ 完整報告(08)
會清資料、會探索、會說故事、能接上模型——這就是資料科學家把原始資料變成決策的核心能力。想深入建模的深水區,ml/scikit-learn 在等你。📈
#data-science
#random-forest
#project
#report
留言 0
留言載入中…