08 專題
實戰:Kaggle 風格完整專案
把前七課全部串起來,走一遍表格資料競賽的標準流程:資料 → 切分 → XGBoost + early stopping → 調參 → 測試集驗收 → SHAP 解讀。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
把前七課全部串起來,走一遍表格資料競賽的標準流程。這是 boosting 模組的收尾,也是你拿到一份新表格資料時該有的工作節奏。
這堂課你會學到
- 串起 boosting 的完整工作流程
- 用驗證集 + early stopping + 隨機搜尋產出一個調好的模型
- 在測試集誠實驗收,並用 SHAP 交出洞察
表格資料的致勝流程
- 切 train/val/test —— 測試集鎖到最後
- 隨機搜尋(或 Optuna) 找好參數
- 最佳參數 + early stopping 重訓,
best_iteration拿最佳樹數 - 測試集驗收 —— classification report + AUC
- SHAP 交出可解釋的洞察
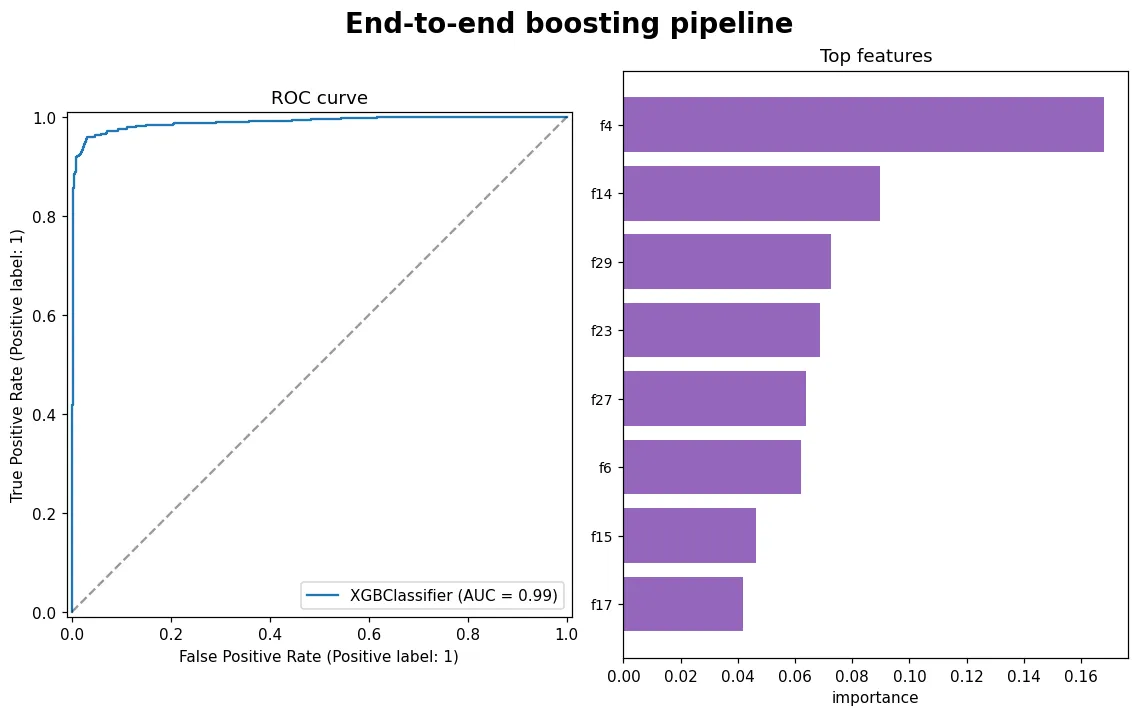
預覽圖就是這條流程的成果:左邊 ROC 曲線驗收模型,右邊模型最看重的特徵。梯度提升是表格資料競賽的長年王者——跑完這課,你就有完整的骨架了。
👉 在 Colab 裡把模型換成 LightGBM,整條流程能否照跑?AUC 差多少?最後挑戰把這套流程套到一個真實的 Kaggle 資料集。
下一個模組,我們離開樹模型,跳進深度學習。
#xgboost
#shap
#pipeline
#kaggle
#end-to-end
留言 0
留言載入中…