04 進階
前處理與 Pipeline
真實資料很少能直接餵給模型。學會用 StandardScaler 標準化、用 Pipeline 把前處理和模型綁成一體,並避開新手最常踩的『資料洩漏』陷阱。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
模型的實力,常常卡在「資料沒整理好」。這堂課把三件讓專業流程與玩具程式碼分野的事情講清楚:標準化、Pipeline、以及新手最常掉進去的資料洩漏陷阱。
這堂課你會學到
- 為什麼靠距離的模型(KNN、SVM…)需要特徵標準化
- 用
StandardScaler標準化,並只在訓練集上fit - 用
Pipeline把「前處理 + 模型」串成一個 estimator - 用
ColumnTransformer+OneHotEncoder處理數值與文字混合的欄位
一條鐵則:任何 fit 只看訓練集
如果你先對全部資料做標準化再切分,測試集的資訊(平均、標準差)就「洩漏」進了訓練過程,評估分數會虛高,上線後現出原形。
鐵則:任何
fit都只能看訓練集。 測試集只能被transform,永遠不被fit。
Pipeline 的價值正在這裡——它把多個步驟綁成單一物件,fit 時自動只在訓練資料上學前處理參數,資料洩漏被結構性地擋掉。而且整條 Pipeline 就是個普通 estimator,可以直接丟進交叉驗證和 GridSearch(後面幾課會用到)。
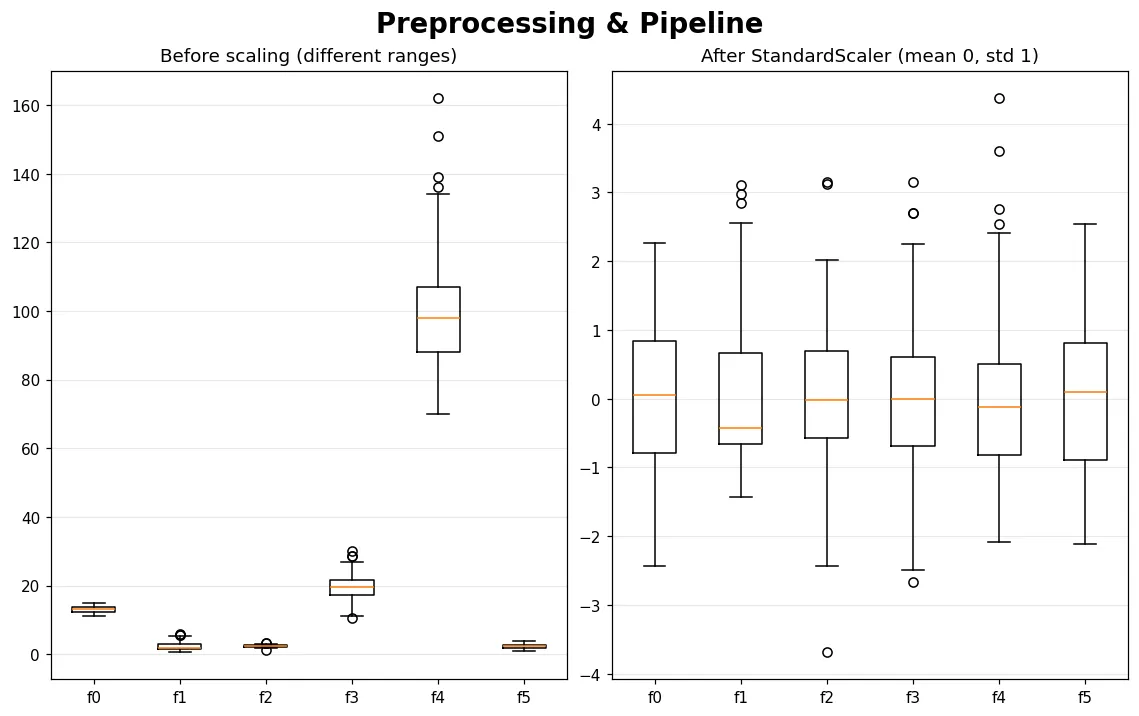
👉 預覽圖就是標準化前後的特徵分布對比。在 Colab 裡比較「有/沒有標準化」的 KNN 準確率,落差會讓你印象深刻。
#scikit-learn
#preprocessing
#pipeline
#standardscaler
#data-leakage
留言 0
留言載入中…