02 入門
資料清理 · 髒資料變乾淨
真實資料總是有缺失、型別不對、有重複、有離群值——垃圾進垃圾出。這堂課把 Titanic 清乾淨:找出缺失值、對症下藥(刪欄 vs 補中位數 vs 補眾數)、處理重複與離群。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
「資料科學家 80% 的時間在清資料,剩下 20% 在抱怨要清資料。」
這句玩笑話很真實。真實資料總是有缺失、型別不對、有重複、有離群值。模型再強,餵髒資料進去也是垃圾進、垃圾出。這課把 Titanic 清乾淨。
清理的四件事
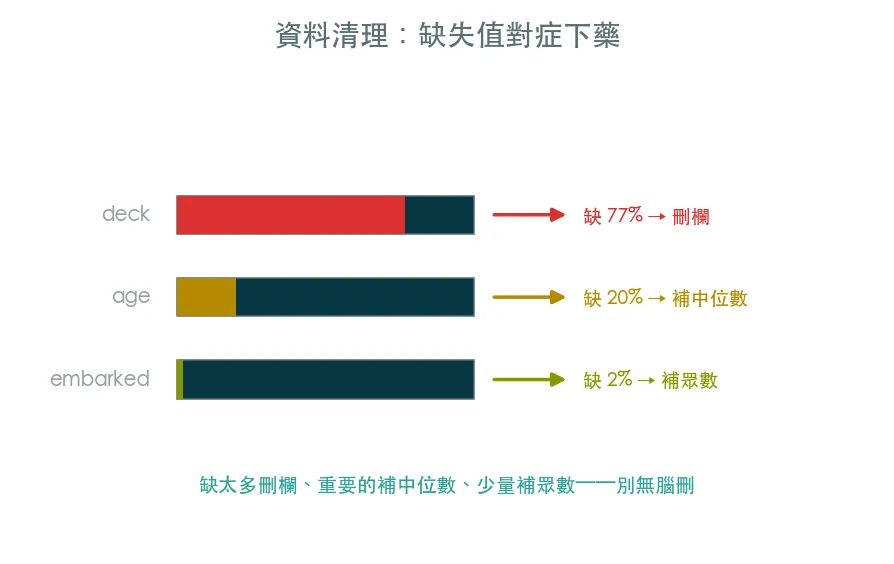
缺失值、型別、重複、離群值。 每一項都有對策,而且要對症下藥——不是無腦刪掉。
這堂課你會學到
- 用
df.isna().sum()盤點缺失值:哪一欄缺幾個 - 缺失值對症下藥:
- 缺太多(deck 缺近 7 成)→ 整欄刪掉
- 重要且缺一些(age)→ 用中位數補(比平均更抗離群)
- 缺很少(embarked)→ 用眾數補
- 處理重複列(直接刪)與離群值(先理解再決定,別反射性刪)
為什麼補值要分情況?
缺失值的處理會直接影響後面所有分析。補錯方法會引入偏差:用平均補一個有極端值的欄位會被拉歪,所以 age 用中位數;deck 缺太多,硬補只是製造假資料,不如刪掉。清理不是機械操作,是基於理解的決策——這正是資料科學的手藝所在。
💡 離群值最容易被誤殺。Titanic 有幾個破千的頭等艙票價,它們不是錯誤、而是真實的極端——刪掉反而丟失了「富人更易生還」這條重要線索。先理解,再決定。
#data-science
#pandas
#data-cleaning
#missing-values
留言 0
留言載入中…