03 入門
探索式分析 EDA · 讓資料說話
資料乾淨後最有趣的一步:用 groupby、樞紐表、相關係數,在建模前先把資料裡的規律挖出來。回答「什麼樣的乘客比較容易生還」——性別、艙等、票價的故事逐漸浮現。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
資料乾淨後,進入最有趣的一步:EDA(Exploratory Data Analysis,探索式分析)。
核心:建模前先讓資料說話
EDA 的目標是在訓練任何模型之前,先用 groupby、樞紐表、相關係數,把資料裡的規律挖出來。你常常會發現:好好做 EDA,答案其實已經呼之欲出,模型只是來確認的。
這堂課你會學到
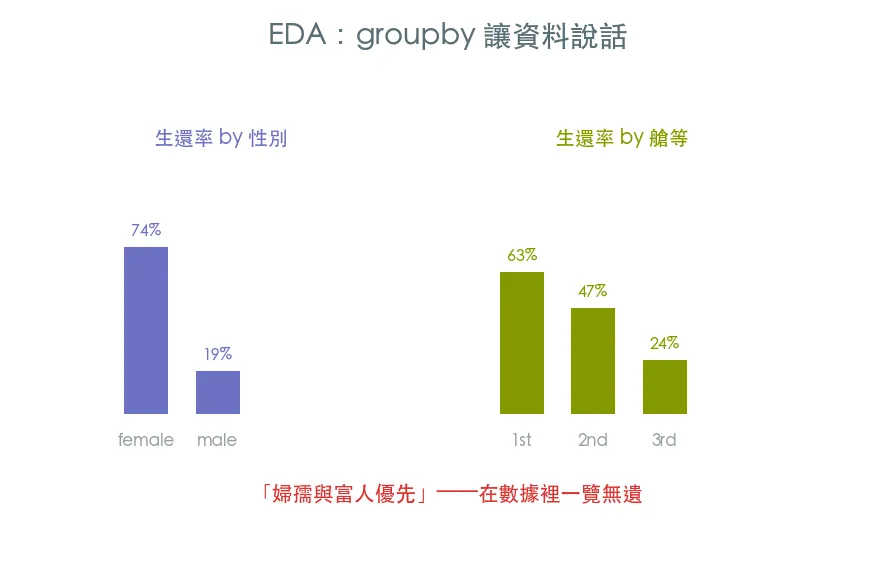
groupby:分組看差異——「女性生還率比男性高嗎?」一行回答pivot_table:兩個因素交叉——「性別 × 艙等」的交互作用corr:數值欄之間的相關係數,看誰跟生還最相關(正負都看)- 三者互補:groupby/樞紐表看類別差異,相關係數看數值關聯
Titanic 的故事浮現
做完這課,生還的關鍵因素會清楚浮現:性別(女性遠高)、艙等(越高越高)、票價(越貴越易生還,因為票價反映艙等)。頭等艙女性生還率接近 100%,三等艙男性最低——「婦孺與富人優先」在數據裡一覽無遺。
EDA 是分析的靈魂
很多新手急著套模型,跳過 EDA,結果模型表現差也不知道為什麼。先理解資料,才知道該做什麼特徵、選什麼模型、結果合不合理。EDA 不是可有可無的前戲,而是整個分析最有價值的一段。
💡 EDA 沒有標準答案,是一個「提問—查證—再提問」的循環。每個發現都會引出下一個問題:女性生還率高,那是不是因為她們多在高艙等?用
pivot_table一交叉就知道。下一課,我們把這些發現畫成圖。
#data-science
#pandas
#eda
#groupby
留言 0
留言載入中…