04 進階
組裝 Transformer
把自注意力和其他零件組裝成完整 GPT:多頭注意力、前饋層、殘差連接、LayerNorm,堆成 Transformer block。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
有了自注意力這顆心臟,這堂課把它和其他零件組裝成一個完整的 GPT:多頭注意力、前饋層、殘差連接、LayerNorm,堆成 Transformer block,再疊成模型。
這堂課你會學到
- 理解多頭注意力:多個注意力頭平行看不同面向
- 認識 block 的四大件:注意力、前饋、殘差連接、LayerNorm
- 組出完整的
MiniGPT,數一數參數量
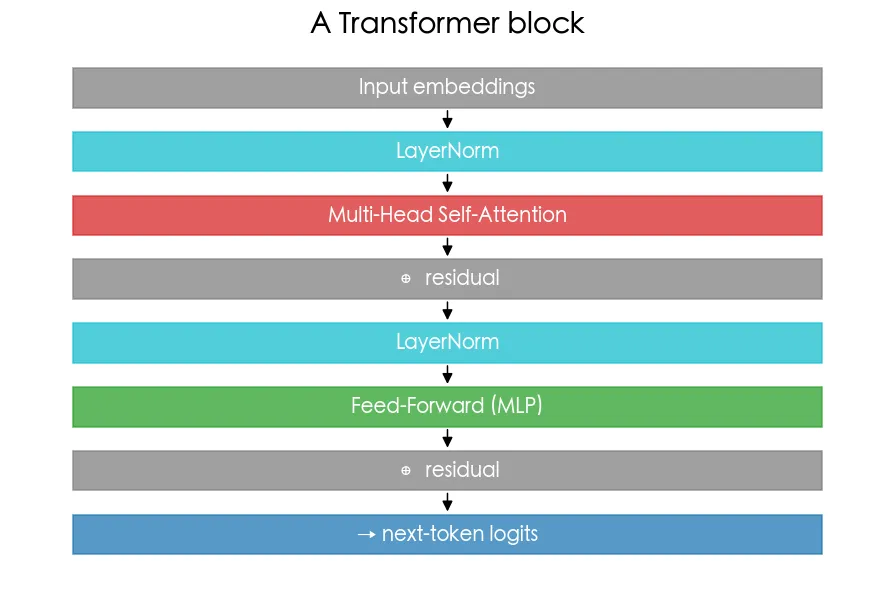
一個 block 的四大件
預覽圖就是一個 Transformer block 的資料流:
- 多頭注意力:把上一課的單頭複製成好幾頭,各自學不同的關注模式,再合併。
- 前饋網路(FFN):每個位置各自過一個小 MLP,做非線性轉換。
- 殘差連接(
x = x + ...):讓梯度好傳、深層也訓得動。 - LayerNorm:穩定每層數值分布,訓練更順。
MiniGPT = token/位置嵌入 → 疊 N 個 block → 輸出頭,對每個位置預測下一個字。我們這隻只有幾十萬參數,是 GPT-3(1750 億)的百萬分之一——但架構一模一樣。
👉 在 Colab 裡對照第 03 課:
MultiHeadAttention裡哪幾行對應「Q·K → 縮放 → 遮罩 → softmax → 加權 V」?
#llm
#transformer
#multi-head
#residual
#layernorm
留言 0
留言載入中…