03 進階
自注意力 Self-Attention
Transformer 的心臟。讓每個位置回頭看前面所有字、自己決定該注意誰。從零實作 Q/K/V 與因果遮罩。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
bigram 笨在「只看前一個字」。自注意力讓每個位置能回頭看前面所有字,並自己決定「該注意誰」。這是 Transformer 的心臟,也是整個 LLM 革命的引擎。這堂課從零把單頭注意力刻出來。
這堂課你會學到
- 理解自注意力要解決什麼:讓 token 之間互相「溝通」
- 親手實作 Query / Key / Value 與縮放點積注意力
- 理解因果遮罩:預測時不能偷看未來
Q / K / V 與不能偷看未來
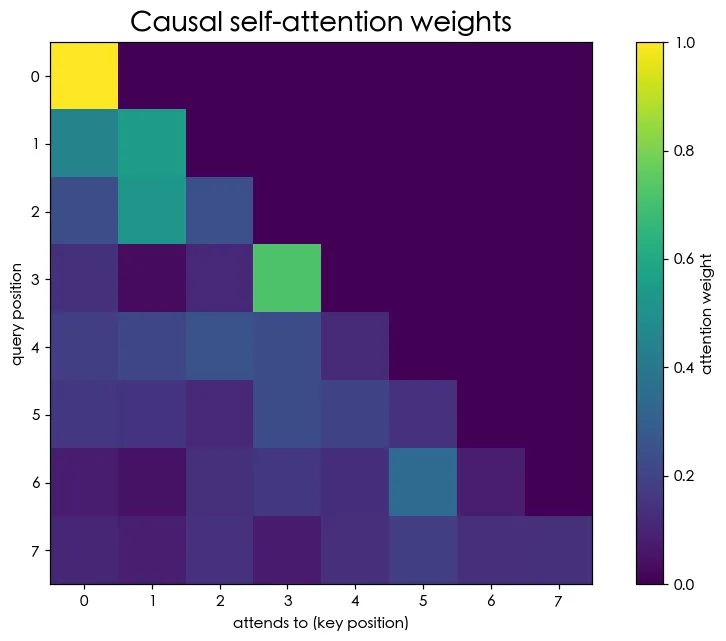
每個 token 產生三個向量:Query(我想找什麼)、Key(我有什麼)、Value(需要我時我給的內容)。每個位置用自己的 Query 和所有位置的 Key 比對,算出「該多注意誰」,再用權重把大家的 Value 加權平均——這樣每個 token 就吸收了它該關注的上下文。
預覽圖是注意力權重矩陣:左下三角有值、右上三角全 0。這是因果遮罩——預測第 3 個字時只能看第 1、2、3 個字,絕不能偷看後面的答案。這正是 GPT 能「邊讀邊預測、又不作弊」的關鍵。
👉 在 Colab 裡把縮放
** -0.5拿掉,看 softmax 後的權重變得多極端——這就是為什麼要「縮放」點積。
#llm
#self-attention
#transformer
#qkv
#causal-mask
留言 0
留言載入中…