02 入門
預測下一個字
LLM 的本質出乎意料地單純:看著前面的文字,預測下一個字。建立這個框架,並訓練一個最陽春的 bigram 基線。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
LLM 的本質出乎意料地單純:看著前面的文字,預測下一個字。把這件事做到極致,就成了會寫文章的模型。這堂課建立這個框架,並訓練一個最陽春的 bigram 模型當基線。
這堂課你會學到
- 理解語言模型 = 「給定前文,預測下一個 token」的機率模型
- 用
get_batch切出「輸入 / 目標」訓練樣本 - 訓練一個 bigram 模型並讓它生成文字(雖然很笨)
預測下一個字,就是一切
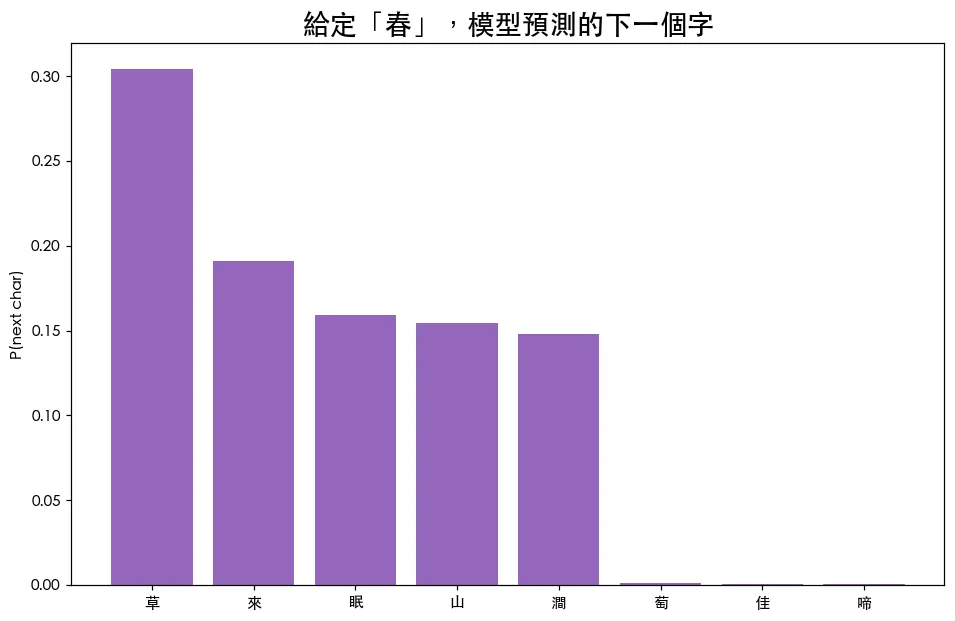
每個位置的「目標」就是它的下一個字——把輸入往右挪一格就是答案。預覽圖顯示:給定「春」,模型吐出對「下一個字是誰」的機率分布。
bigram 只看前一個字,所以生成必然不通順——它記不住上下文。但訓練 → 生成的骨架已經完整。要讓它變聰明,模型得學會「往前看更多字」,這正是下一課自注意力要解決的問題。
👉 在 Colab 裡把生成的開頭字換掉,或印出 bigram 學到「春」後面最常接的字,看它抓到了什麼。
#llm
#language-model
#bigram
#sampling
留言 0
留言載入中…