01 入門
斷詞 Tokenization
電腦只看得懂數字。Tokenization 把文字切成 token、再對應成數字——所有 LLM 的入口。從字元級到 BPE。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
歡迎來到 大型語言模型 → 從零打造迷你 GPT。
這個軌道不教你「呼叫 ChatGPT」,而是帶你親手把一個 GPT 從零刻出來——從斷詞、注意力、Transformer,一路到訓練、生成、對齊。模型刻意做得很小、功能很爛,重點是徹底搞懂裡面到底發生什麼事。
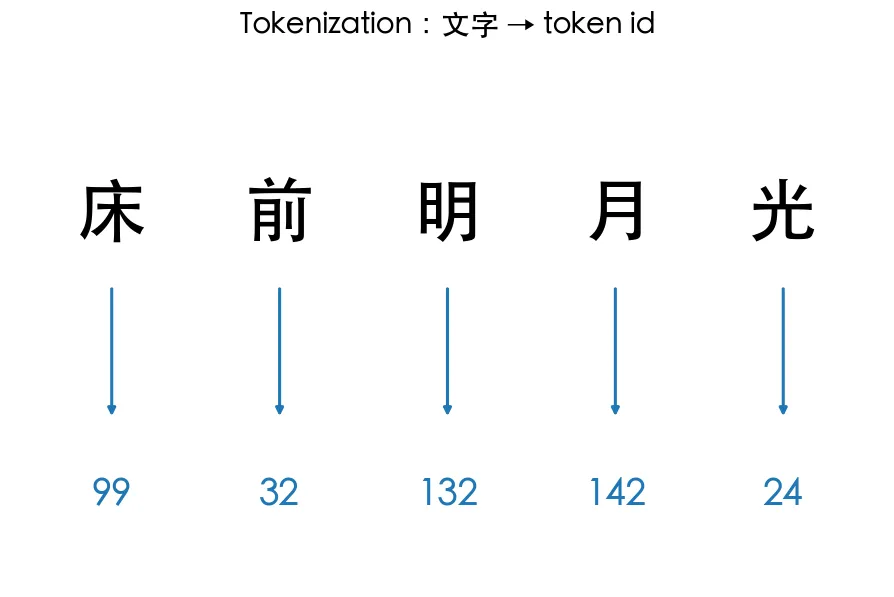
第一步:電腦看不懂文字,只看得懂數字。Tokenization(斷詞) 就是把文字切成一個個 token、再對應成數字的過程。
這堂課你會學到
- 理解 token 是 LLM 的「原子」
- 實作最簡單的字元級斷詞:
encode/decode - 理解 BPE(子詞斷詞) 的核心想法——真實 LLM 用的方法
從字元級到 BPE
預覽圖就是字元級斷詞:每個字配一個編號,encode 把文字變數字、decode 變回來。簡單,但序列會很長、也學不到「詞」的概念。
真實的 GPT 用 BPE(Byte Pair Encoding):從字元開始,反覆把最常一起出現的相鄰一對合併成新 token,直到詞表夠大。常見的詞變單一 token、罕見的詞才拆成小塊。本軌道為了簡單,後面一律用字元級——概念一樣,少了工程細節。
👉 本軌道建議先學完
ml/pytorch(需要 PyTorch 基礎)。在 Colab 裡把 BPE 的合併次數加大,看會併出哪些 token。
#llm
#tokenization
#bpe
#gpt
留言 0
留言載入中…