05 進階
文字條件 · 一句話如何導引生成
我們的迷你模型只會隨機生數字。真正的 Stable Diffusion 能聽懂「一隻沙灘上的柯基」,靠的是文字條件:CLIP 把 prompt 變成向量、cross-attention 注入去噪。親眼見證 CLIP 把文字與影像對齊。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
到目前為止,我們的迷你擴散模型只會隨機生數字——沒辦法叫它「生一個 7」。真正的 Stable Diffusion 能聽懂「一隻在沙灘上的柯基」,靠的是文字條件(text conditioning)。
兩個關鍵零件
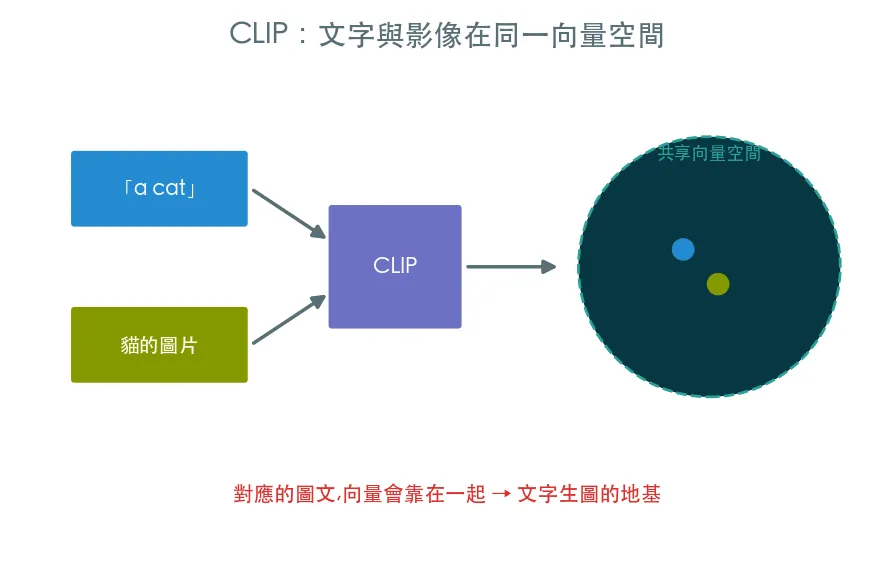
- 文字編碼器(CLIP):把一句 prompt 變成一個向量。CLIP 的神奇之處是它讓文字向量和影像向量活在同一個空間——「貓」的文字向量,會靠近貓的圖片向量。
- 交叉注意力(cross-attention):在 U-Net 去噪的每一步,把這個文字向量「注入」進去,引導生成往 prompt 描述的方向走。
這堂課你會學到
- 載入 CLIP,它同時有「看圖」和「讀字」兩個編碼器
- 親眼見證 CLIP 把文字與影像對齊:給一張圖、幾句描述,它能說出哪句最配——而且不需訓練
- 理解文字生圖 = 你手刻的去噪過程 + 文字向量透過 cross-attention 的引導
CLIP:連接語言與視覺的橋
CLIP 用海量「圖+說明」對訓練,逼文字編碼器與影像編碼器把「對應的圖文」放到向量空間的相近位置。結果就是一個神奇的能力:不用為特定任務微調,就能判斷一張圖配不配一句話。這個「共享語意空間」正是文字生圖的地基——有了它,prompt 才能變成去噪過程聽得懂的引導訊號。
你離 Stable Diffusion 只差這一塊
回顧一下:你已經手刻了加噪(02)、去噪 U-Net(03)、快速取樣(04)。現在補上文字條件這一塊,Stable Diffusion 的骨架就完整了。下一課用 diffusers 跑真正的 SD 時,你會認得裡面每一個零件——因為它們你都親手碰過。
💡 cross-attention 是 Transformer 的核心機制,你在
llm軌道手刻過自注意力。文字生圖把它用在「讓影像特徵去『查詢』文字向量」——同一個機制,跨模態的應用。下一課,見證完整的文字生圖。
#diffusion
#clip
#text-conditioning
#cross-attention
留言 0
留言載入中…