08 專題
對齊 ②:RLHF 與 DPO
讓輸出對齊人類偏好,靠的是 RLHF——ChatGPT 的祕方。講清楚 RLHF 概念,並親手實作它的精簡替代品 DPO。整條學習線的終點。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
SFT 教模型「照格式回答」,但答得好不好、合不合人類喜好是另一回事。讓輸出對齊人類偏好,靠的是 RLHF(人類回饋強化學習)——ChatGPT 的祕方。這堂課講清楚 RLHF 的概念,並親手實作它的精簡替代品 DPO。這是本軌道、也是整條學習線的終點。
這堂課你會學到
- 理解 RLHF 的三步驟與它為什麼複雜
- 理解 DPO 如何用一個簡單的損失達到類似效果
- 親手在迷你模型上跑 DPO,看它越來越偏好「好的回應」
RLHF 的精簡替代品:DPO
RLHF 靠三步:SFT → 訓練獎勵模型(找人對回答排序)→ 用 RL(PPO)微調。有效,但要訓練額外模型、還要跑不穩定的強化學習,很複雜。
DPO(Direct Preference Optimization) 證明了:你不需要獎勵模型、也不需要 RL。只要有一堆「偏好配對」(同一提示下,一個較好的 chosen、一個較差的 rejected),就能用一個簡單的分類損失,直接把模型往「偏好 chosen」推。
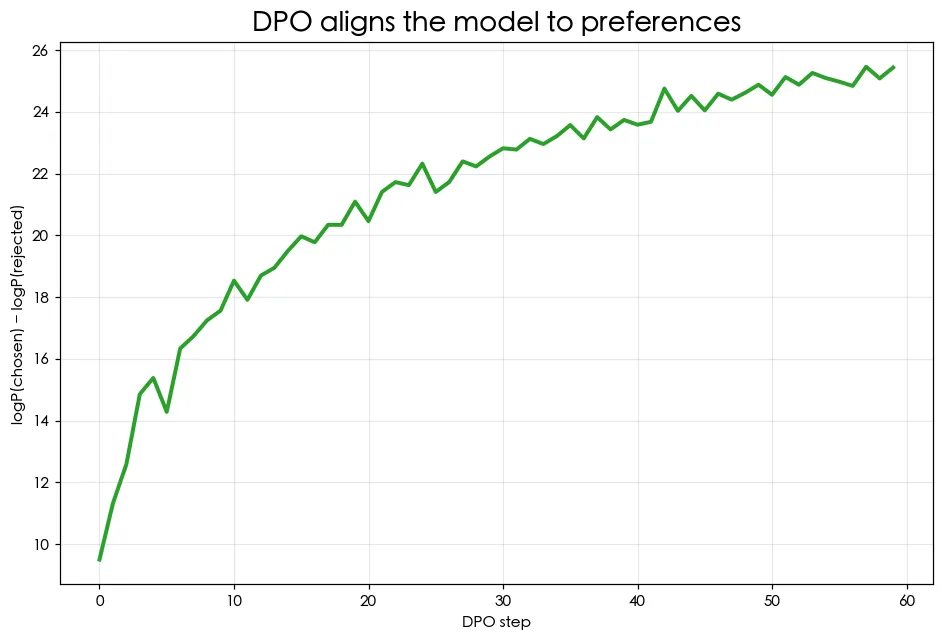
預覽圖是 DPO 的成果:margin(chosen 與 rejected 的對數機率差)一路往上——模型越來越偏好正確答案。我們沒訓練任何獎勵模型、也沒跑 RL,只用一個損失就把模型對齊了人類偏好。
從第 01 課的斷詞,到自注意力、Transformer、訓練、KV cache、SFT、DPO——你從零親手打造並對齊了一個語言模型。真實的 GPT 只是把每一塊放大幾百萬倍、資料多幾億倍,原理你已經全部掌握了。
🎓 走完從零打造 LLM 的旅程。下一個前沿是 AI Agent——讓模型不只會說話,還會用工具、做事情。
#llm
#rlhf
#dpo
#alignment
#preference
留言 0
留言載入中…