04 進階
影像辨識:從全連接到 CNN
處理真實影像 MNIST。先用全連接網路當基線,再升級到 CNN——看看為什麼卷積特別適合影像。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
這堂課處理真實影像——MNIST 手寫數字。先用全連接網路當基線,再升級到 CNN(卷積神經網路),看看為什麼卷積特別適合影像。
這堂課你會學到
- 載入 MNIST,用
DataLoader分批餵資料 - 理解
nn.Conv2d/ 池化在做什麼、為何適合影像 - 比較全連接網路與 CNN 的準確率
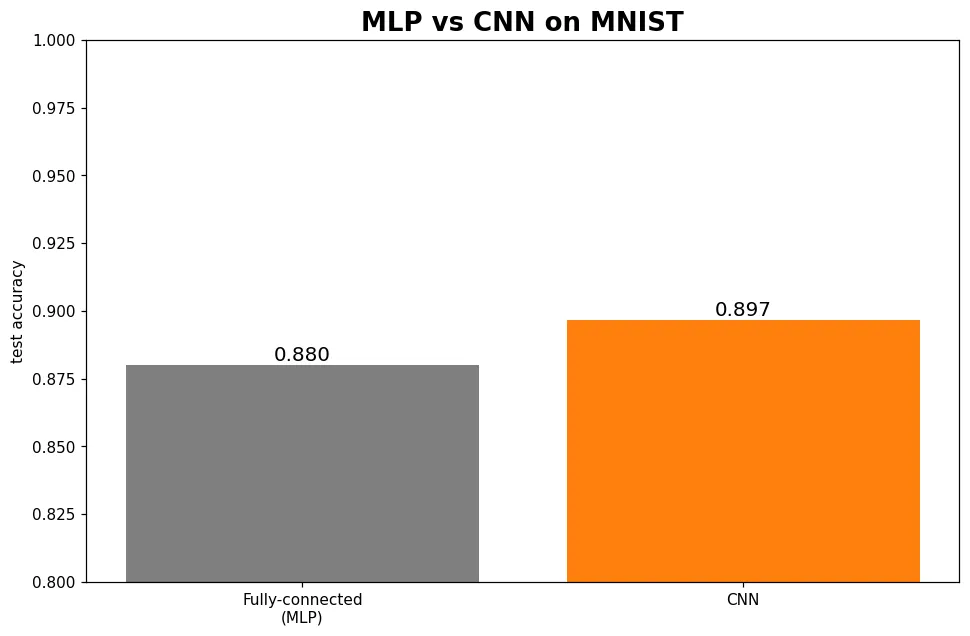
卷積為什麼贏?
把 28×28 的圖攤平成 784 維向量丟進全連接網路,能用,但攤平就把「哪個像素挨著哪個」的空間結構全丟了。
卷積層則用一個小窗口(kernel)滑過整張圖,偵測邊緣、轉角等局部圖樣,而且同一個 kernel 在每個位置共用權重——既保留空間結構、參數又少。
預覽圖就是結果:同樣的資料與訓練量,CNN(約 94%)明顯贏過全連接網路(約 89%),因為它尊重影像的空間結構。這也是為什麼所有現代視覺模型都建立在卷積(或其變體)之上。
👉 在 Colab 裡把訓練資料從子集改成全部 6 萬筆,看 CNN 準確率衝到多少。
#pytorch
#cnn
#convolution
#mnist
#image
留言 0
留言載入中…