05 進階
物件偵測 · 不只是什麼,還要在哪裡
分類一張圖回一個標籤,但真實場景一張圖常有很多東西。物件偵測同時回答有什麼、在哪裡——框出每個物件的邊界框、類別與信心。用業界最當紅的 YOLO 開箱即用做推論。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
前四課都在做分類——一張圖回一個標籤。但真實世界一張圖裡常有很多東西:一條街上有車、有人、有號誌。物件偵測更進一步。
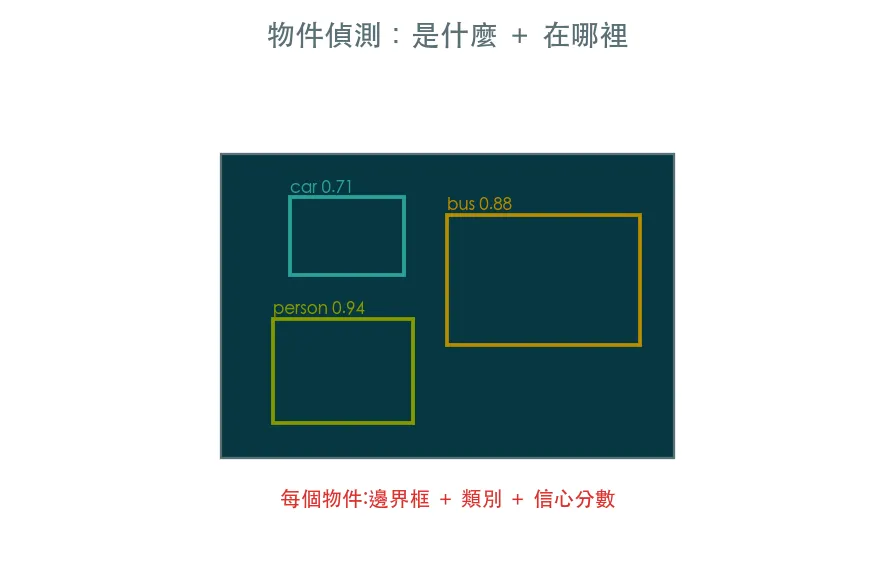
核心:同時定位與分類
物件偵測同時回答「有什麼」與「在哪裡」——框出每個物件的邊界框(bounding box)、給出類別與信心分數。
自動駕駛、安防監控、醫療影像、零售盤點……都靠它。
這堂課你會學到
- 用業界最當紅的 YOLO(You Only Look Once,透過
ultralytics套件)做推論 - 載入在 COCO(80 類)上預訓練好的
yolov8n,開箱即用——丟一張圖就有結果 - 讀出結構化結果:每個框的類別、信心、座標
- 換上你自己的圖(任何網址),試試多物件的場景
為什麼用現成的 YOLO?
物件偵測模型的架構(anchor、NMS、多尺度特徵…)相當複雜,從零刻一個既費時又難調。業界的務實做法是直接用成熟框架的預訓練模型,要偵測自己的類別時再用標註資料微調(model.train(...),同遷移學習精神)。這堂課讓你先把「能用」這件事跑通,建立全局感。
💡
ultralytics的 YOLO 系列同時支援偵測、分割、姿態估計、分類,介面統一。學會這一套,等於拿到視覺任務的瑞士刀。下一課就用它的分割版,把方框升級成像素級輪廓。
#cv
#object-detection
#yolo
#ultralytics
留言 0
留言載入中…