06 進階
影像分割 · 逐像素看懂畫面
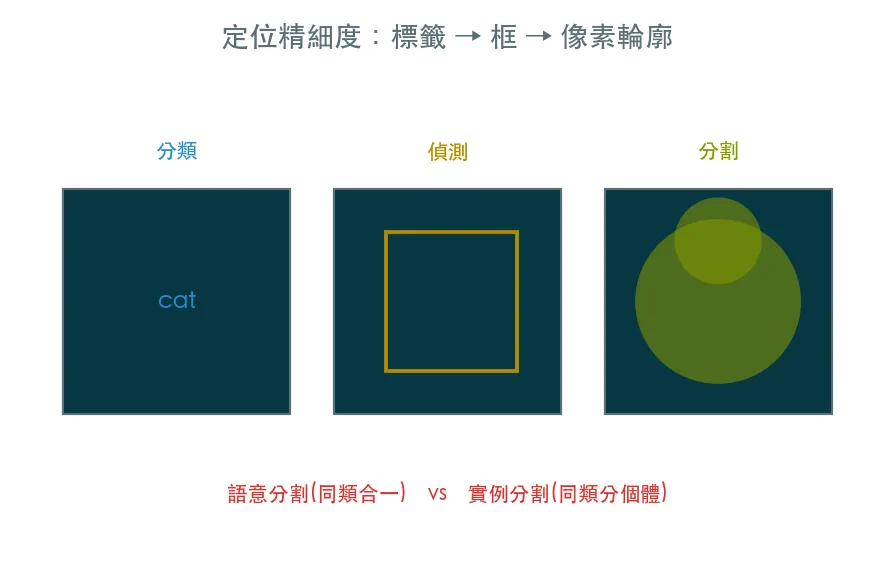
偵測畫的是方框,方框裡仍混著背景。影像分割替每一個像素分類,精確切出物件輪廓。分語意分割(同類合一)與實例分割(同類分個體),用 YOLO-seg 實作實例分割。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
偵測畫的是方框,但方框裡仍混著背景。影像分割更精細——它替每一個像素分類,精確切出物件的輪廓。
兩種分割
- 語意分割(semantic):同類的像素一視同仁——所有「人」是同一片、所有「道路」是同一片。適合理解整片區域。
- 實例分割(instance):同類也分開個體——人 1、人 2、人 3 各一片。適合數個體、各自切開。
醫療影像(切腫瘤)、影像去背、自駕的可行駛區域偵測,都靠分割。
這堂課你會學到
- 用 YOLO 的分割版(
yolov8n-seg)做實例分割,每個物件疊上半透明輪廓遮罩 - 看懂遮罩(mask)的本質:一張和影像同尺寸的 0/1 張量,屬於物件的像素是 1
- 遮罩能拿來做什麼:去背、填色、算面積、做後續處理
- 兩條技術路線怎麼選:實例(YOLO-seg,物件導向)vs 語意(deeplabv3,像素導向)
偵測 → 分割,是同一條精細化的路
分類(整張一個標籤)→ 偵測(方框)→ 分割(像素輪廓),是「定位精細度」一路提升的三個層級。你需要多精細,就選哪一級——不是越精細越好,而是匹配任務:要數人頭用偵測就夠,要做去背才需要分割。
💡
ultralytics把偵測與分割收在同一套 API,換個權重檔(-seg)就切換。要語意分割,torchvision 內建的deeplabv3是業界標準選擇。下一課換個方向:打開分類模型的黑盒子,看它到底在看哪裡。
#cv
#segmentation
#yolo
#mask
留言 0
留言載入中…