08 專題
端到端實戰 · 完整影像分類專案
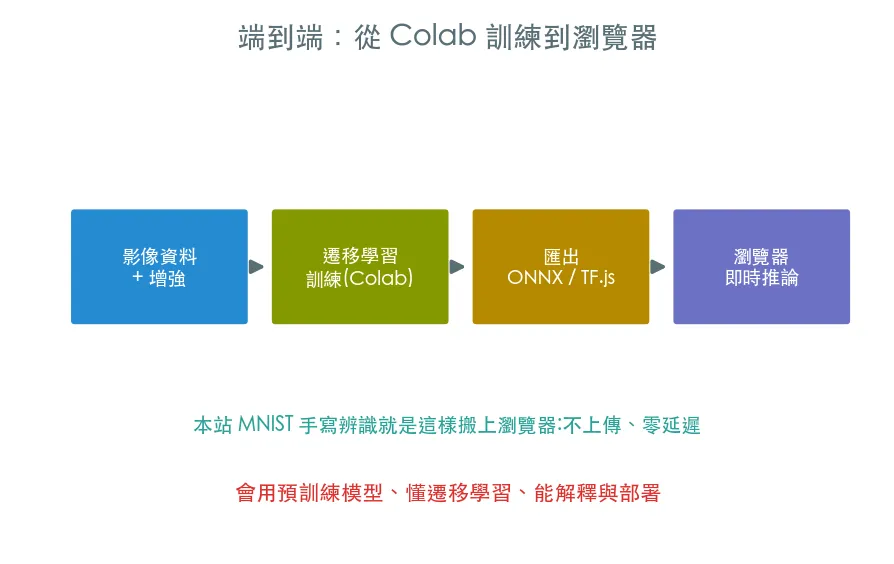
整條軌道的收尾。把遷移學習 + 資料增強串成一個完整流程:訓練分類器、對單張圖做 Top-3 推論、存檔,最後聊怎麼把模型匯出成 ONNX/TF.js 部署到瀏覽器——呼應本站 MNIST 手寫辨識的做法。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
整條軌道的收尾。把前面學到的東西串成一個完整流程:遷移學習 + 資料增強訓練一個分類器,對單張圖做推論,存檔,最後聊怎麼部署到瀏覽器——呼應本站的做法。
這堂課你會做完整一輪
- 組裝資料管線:遷移學習(預訓練 ResNet-18)+ 資料增強(隨機翻轉)
- 凍結 backbone、只訓練新分類頭(快又準)
- 評估測試準確率
- 單張圖推論 demo:拿一張測試圖,看模型最有把握的 Top-3 預測
- 存檔,並走一遍部署思路
從 Colab 到瀏覽器:本站怎麼做
本站的 MNIST 手寫辨識等小工具,就是把訓練好的視覺模型搬進瀏覽器即時跑:
- 模型在 Python/Colab 訓練好後,匯出成 ONNX 或 TF.js 格式。
- 前端用 TensorFlow.js / onnxruntime-web 載入,在使用者瀏覽器本地推論——不需要伺服器、不上傳影像、零延遲。
- 這跟
rl軌道把 agent 權重匯出到瀏覽器是同一套思路:Colab 訓練 → 匯出 → 前端即時推論。
軌道小結
你從影像即張量,一路做到能解釋、能偵測、能上線:
- 影像張量 / 前處理(01)→ CNN on CIFAR(02)
- 遷移學習(03)→ 資料增強(04):用更少資源做更準的分類
- 物件偵測 YOLO(05)→ 影像分割(06):從「是什麼」到「在哪裡、什麼形狀」
- Grad-CAM 可解釋性(07)→ 端到端專案 + 部署(08)
會用預訓練模型、懂遷移學習、能解釋與部署——這正是業界電腦視覺工程師的日常工具箱。📷
#cv
#transfer-learning
#deployment
#project
留言 0
留言載入中…