08 專題
端到端實戰 · 訓練 agent 玩接水果
整條軌道的收尾。拿第七課自訂的 CatchEnv,用 stable-baselines3 訓練一個真的會接水果的 agent,評估、存檔,最後聊聊怎麼把訓練好的模型搬進瀏覽器——正是本站遊戲區 RL 的做法。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
整條軌道的收尾。我們把前面所有東西串起來:拿第 07 課親手刻的 CatchEnv,用 stable-baselines3 訓練一個真的會接水果的 agent,評估它、存檔,最後聊一件最有意思的事——怎麼把訓練好的模型搬進瀏覽器,讓它在網頁裡即時玩遊戲。這正是本站遊戲區 RL 的真實做法。
這堂課你會做完整一輪
- 把 CatchEnv 包上
TimeLimit,組成訓練環境 - 先量一個隨機策略基準(等下好對照)
- 用 PPO 訓練十萬步
- 評估:跟基準比,進步多少
- 看 agent 實際玩一回合——木板會主動移到水果正下方去接
- 存檔 / 載入模型,日後直接推論不用重訓
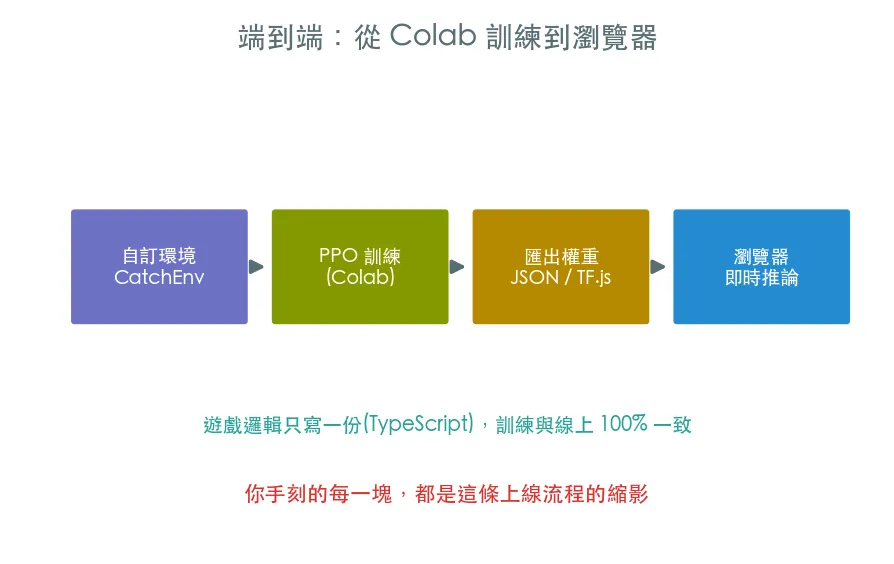
從 Colab 到瀏覽器:本站怎麼做
你訓練的 agent 現在活在 Python 裡。本站的遊戲區把同樣的流程搬上線,讓 RL agent 直接在你的瀏覽器裡玩遊戲。三招關鍵:
- 遊戲邏輯只寫一份(TypeScript):遊戲的
GameCore用 TypeScript 寫,瀏覽器直接用;Python 訓練時則用 PyMiniRacer(V8 引擎) 跑同一份 JS,確保「訓練時的遊戲規則」與「線上的遊戲規則」100% 一致——規則不會有兩套、不會 drift。 - Gymnasium 包裝:Python 端寫一個
gym.Env把那份 JS 的reset/step包起來——就像你這課對 CatchEnv 做的——交給 stable-baselines3 訓練。 - 匯出權重給瀏覽器:訓練好的策略網路權重匯出成 JSON / TF.js 格式,前端載入後即可在瀏覽器即時推論。
想看真實版本,翻 repo 的
ml-training/與遊戲區的GameCore架構。你這條軌道學的每一塊——環境介面、PPO 訓練、模型存檔——都是那套上線流程的縮影。
軌道小結
你從完全不懂 RL,一路手刻到能訓練 agent 玩自製遊戲:
- 世界觀(01)→ Q-learning(02)→ DQN(03):value-based 一路打通
- stable-baselines3(04):站在巨人肩上
- 策略梯度 REINFORCE(05):policy-based 的根
- 獎勵塑形與包裝器(06)→ 自訂環境(07)→ 端到端 + 上線(08)
原理你手刻過、工具你也會用——這正是把強化學習用在真實問題上需要的兩種底氣。🎮
#rl
#ppo
#stable-baselines3
#project
留言 0
留言載入中…