01 入門
影像即張量 · torchvision 的入口
在電腦眼裡,一張彩色影像就是一個 [C,H,W] 張量。這堂課用 torchvision 載入 CIFAR-10,看懂影像的形狀、像素範圍,以及正規化這個視覺模型幾乎必做的前處理。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
歡迎來到 電腦視覺 → 深度電腦視覺。
這條軌道假設你已經學過 ml/pytorch(會 tensor、autograd、訓練迴圈、CNN 基礎)。我們不重教這些,而是直接做視覺專屬的進階主題:遷移學習、資料增強、物件偵測、影像分割、可解釋性。
第一步:把最根本的觀念釘牢
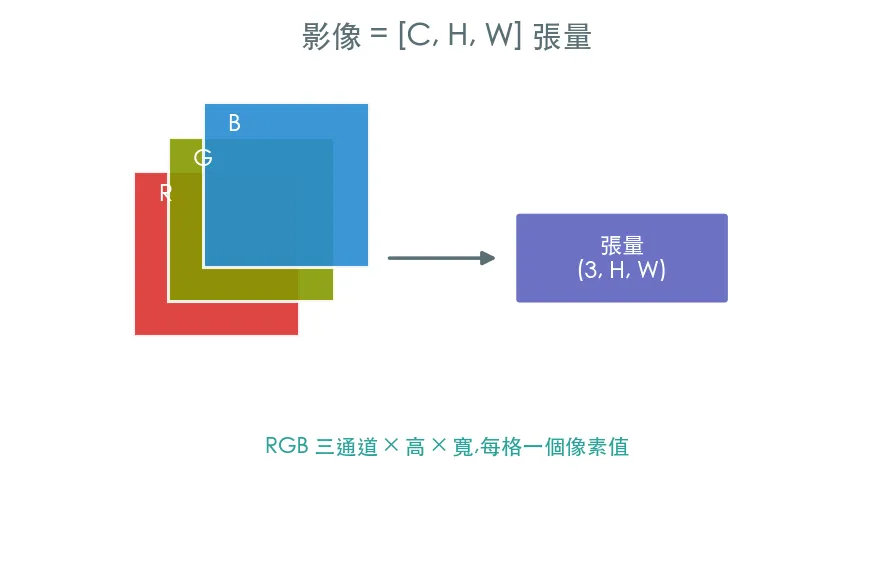
在電腦眼裡,一張彩色影像就是一個形狀
[C, H, W]的張量——3 個顏色通道(RGB)× 高 × 寬,每個數字是一個像素強度。所有視覺模型,吃的都是這個張量。
理解了這點,「影像處理」就不再神祕——它只是對一個三維數字陣列做運算。
這堂課你會學到
- 用 torchvision 一行載入 CIFAR-10(6 萬張 32×32 彩色小圖,10 類)
- 看懂一張影像的形狀
(3, 32, 32)與像素範圍(ToTensor把 0–255 縮到 0–1) - 用
DataLoader一次拿一批,把影像排成 grid 視覺化 - 正規化(Normalize):用平均/標準差把輸入置中,讓訓練更穩、更快——視覺模型幾乎必做
為什麼從 CIFAR-10 開始?
它夠小(秒下載、好訓練),又夠真實(彩色、有背景雜訊,比 MNIST 難得多)。整條軌道很多課都會回到它,讓你專注在「方法」而不是「資料工程」。
👉 建議先學完
ml/pytorch。這課純看資料、不訓練,Colab 不開 GPU 也行。
#cv
#torchvision
#cifar
#tensor
留言 0
留言載入中…