01 入門
生成模型的世界觀 · 從加噪到去噪
前面的軌道讓模型辨識影像,這條軌道讓模型創造影像。比較 VAE/GAN/Diffusion 三條路線,並親眼看擴散的前向過程——把一張數字一步步加噪成雪花,建立「破壞是為了學會重建」的心智模型。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
歡迎來到 生成式影像 → 擴散模型生成影像。
前面的軌道讓模型辨識影像(分類、偵測、分割)。這條軌道反過來:讓模型創造影像。能無中生有畫出一張圖的模型,叫生成模型。
三條路線的直覺
- VAE:學會把圖壓成一個小向量、再還原。生成 = 從向量空間取一點解碼。圖通常偏糊。
- GAN:一個「畫家」和一個「鑑定師」對抗訓練。圖很銳利,但訓練不穩、容易崩。
- Diffusion(擴散):今天的主流(Stable Diffusion、Midjourney、DALL·E 都是)。點子優雅到不可思議——
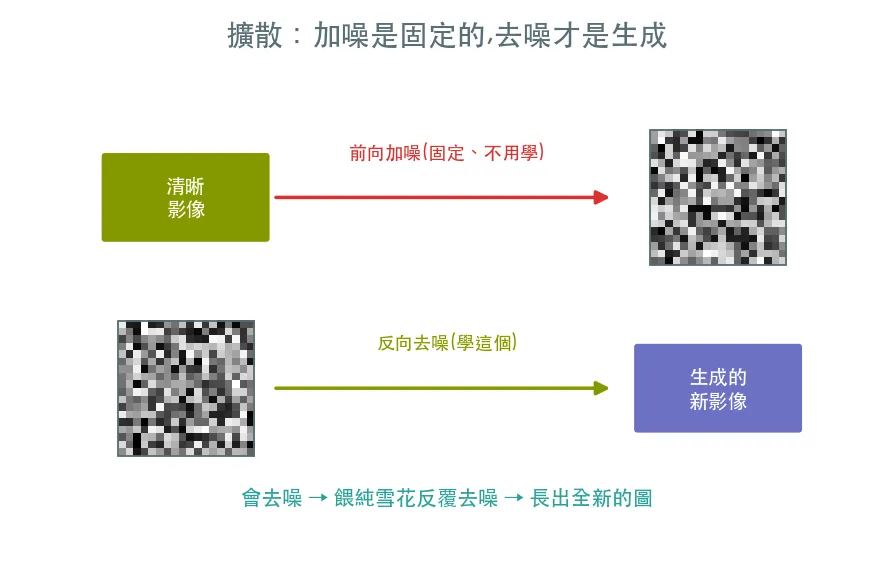
先學會「把圖一步步加噪變成雪花」,再反過來「從雪花一步步去噪還原成圖」。 會去噪,就會生成:餵一張純噪聲進去,反覆去噪,就「長」出一張全新的圖。
這堂課你會學到
- 三種生成模型(VAE / GAN / Diffusion)的核心直覺與取捨
- 親眼看擴散的前向過程:把一張 MNIST 數字一步步加噪,直到變成純雪花
- 建立「破壞是為了學會重建」的心智模型——整條軌道的靈魂
為什麼擴散贏了?
GAN 銳利但難馴,VAE 穩定但模糊。擴散把「生成」拆解成「許多次微小的去噪」,每一步都是個容易學的小任務,合起來卻能生出驚人細節——既穩定又高品質。理解了「加噪→去噪」這個顛倒的思路,你就掌握了當代影像生成的核心。
👉 這條軌道理念同
llm軌道:功能不求強,重在徹底理解機制。先手刻一個 MNIST 迷你版(02–04),再用 diffusers 玩真正的 Stable Diffusion(06–08)。建議先學ml/pytorch。
#diffusion
#generative
#vae
#gan
留言 0
留言載入中…