06 進階
獎勵塑形與環境包裝器
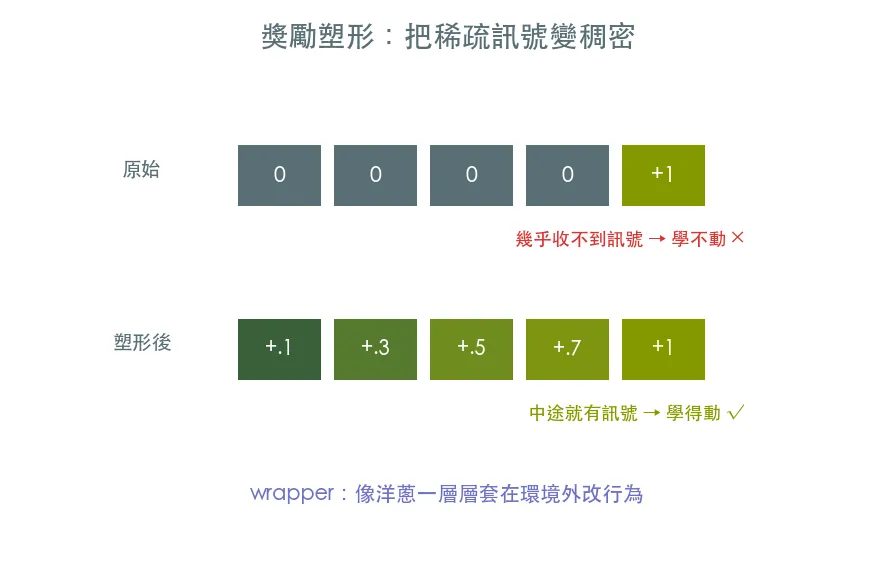
獎勵很稀疏時 agent 收不到訊號、根本學不動。兩個救星:環境包裝器(像洋蔥一層層套在環境外改行為)與獎勵塑形(自己加中途獎勵,把稀疏訊號變稠密)。在難纏的 MountainCar 上實戰。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
到目前為止,環境的獎勵都算「好心」——CartPole 每撐一步就給 +1,訊號很密。但真實世界常常很殘酷:獎勵極度稀疏。
經典的反派是 MountainCar:一台動力不足的小車要爬上山頂,但只有到山頂才給獎勵。隨機亂動幾乎永遠到不了山頂,agent 收不到任何正向訊號、根本不知道自己有沒有在進步——學不動。這是 RL 在真實問題上最常見的痛點。
兩個救星
環境包裝器(wrapper):像洋蔥一樣一層層套在環境外,改觀察、改獎勵、限制步數,而完全不動原環境的程式。
獎勵塑形(reward shaping):自己加一點「中途獎勵」引導 agent,把稀疏訊號變稠密。
這堂課你會學到
- 疊用內建包裝器:
TimeLimit(步數上限)、RecordEpisodeStatistics(自動記錄每回合) - 寫一個自訂
RewardWrapper:用「能量」(高度 + 速度²)當塑形訊號,引導小車學會來回擺盪蓄能 - 寫一個
ObservationWrapper:把觀察正規化到 0~1,讓演算法吃得更穩 - 親眼比較:塑形前後,同樣亂走拿到的訊號稠密度差多少
塑形的雙面刃
獎勵塑形威力強大,但有個著名的陷阱:你獎勵什麼,agent 就最大化什麼——包括你沒料到的鑽漏洞方式。如果中途獎勵設計不當,agent 可能學會「在原地刷分」而不是真的完成任務。所以塑形是門手藝:要引導方向,又不能讓捷徑比正解更划算。這堂課會帶你體會這個分寸。
💡 包裝器是把 RL 用在真實問題上最實用的一組工具。下一課我們就用這套思路,親手把一個小遊戲包成完整的 gymnasium 環境。
#rl
#reward-shaping
#gym-wrappers
#mountaincar
留言 0
留言載入中…