策略梯度 · 直接學一個策略
DQN 那一家先學 Q 值再推動作;策略梯度反過來,直接把策略參數化成神經網路,讓帶來高報酬的動作機率變大。這堂課手刻 REINFORCE——PPO、A2C 等現代演算法的共同祖先。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
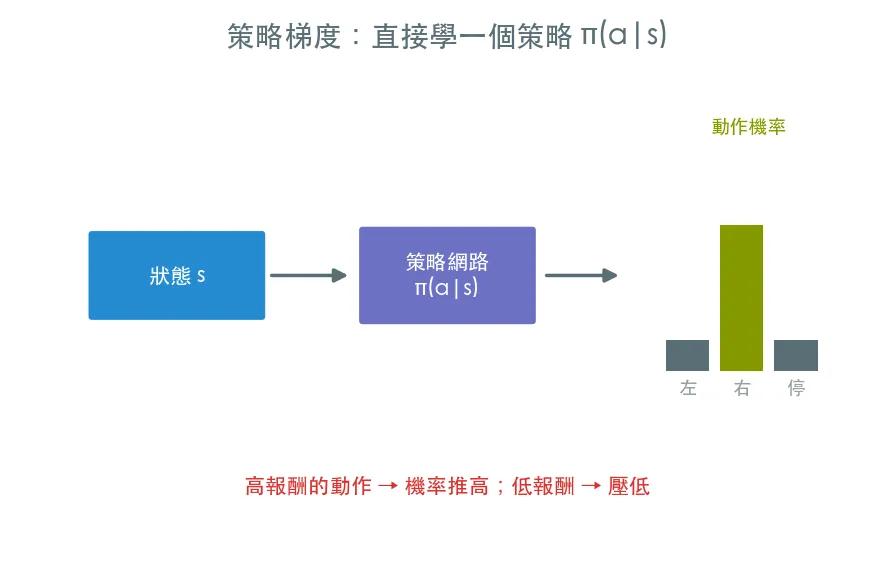
RL 有兩大家族。DQN 那一家(value-based)是先學 Q 值,再從 Q 值推出動作。這一課認識另一家——策略梯度(Policy Gradient),它走一條更直接的路:
直接把策略 π(a|s) 參數化成一個神經網路,輸入狀態、輸出每個動作的機率,然後讓「帶來高報酬的動作」機率變大、「帶來低報酬的動作」機率變小。
不繞 Q 值,直接優化「該怎麼做」本身。我們手刻這家最基礎的演算法 REINFORCE——它是 PPO、A2C 這些現代主力的共同祖先。
這堂課你會學到
- 策略網路:用 softmax 輸出動作機率,用
Categorical分布取樣動作(取樣本身就是探索) - REINFORCE 的更新邏輯:跑完一整回合 → 算每步的折扣後報酬 → 用
loss = −Σ log π(a|s)·return更新 - 為什麼 return 標準化能讓訓練穩定一大截
- 畫學習曲線,看策略慢慢變強
直覺:好的動作,推它一把
REINFORCE 的精神出奇地簡單:跑一回合,看最後拿到多少報酬。報酬高,就提高這回合所有動作的機率;報酬低,就壓低。 久而久之,常出現在「高報酬回合」裡的動作機率越來越高,策略就越來越好。−Σ log π · return 這條 loss,數學上就是在做這件事。
它跟 PPO 的關係
REINFORCE 有個毛病:更新幅度不受控,有時一步跨太大就把好不容易學到的策略毀了。PPO 就是在這個骨架上加了「每次別偏離舊策略太多」的護欄。所以學會這一課,你其實已經摸到了 PPO 的根——上一課那個黑盒子,核心就在這裡。
💡 value-based(DQN)vs policy-based(策略梯度)是 RL 的兩條主線,各有擅場。現代演算法(如 actor-critic)常常兩者並用。手刻過這兩家,你就有了讀懂任何 RL 論文的地圖。
留言 0
留言載入中…