04 進階
站在巨人肩上 · stable-baselines3
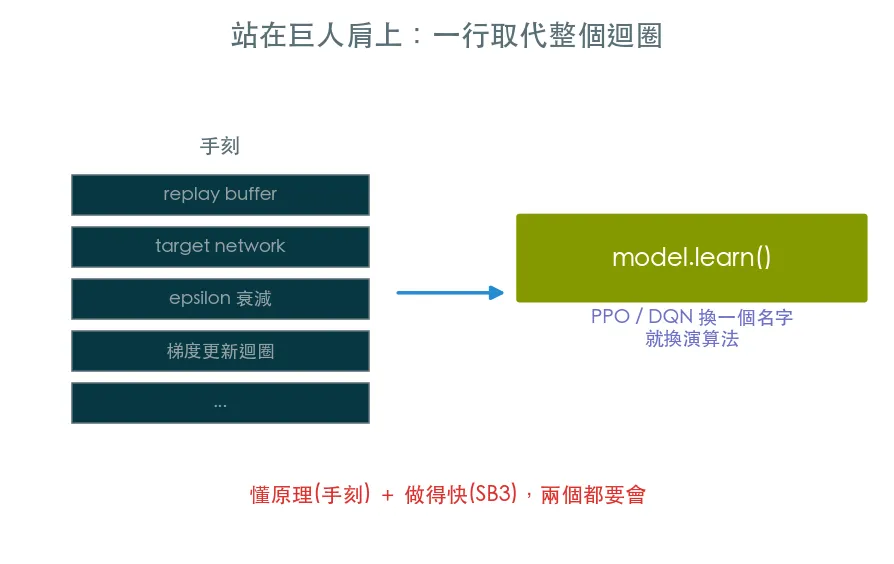
手刻 DQN 讓你懂原理,但做專案沒人每次重寫訓練迴圈。stable-baselines3 把 DQN、PPO 等演算法封裝成幾行就能用的可靠實作。一行 model.learn() 取代整個迴圈,並用 TensorBoard 監控訓練。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
上一課手刻 DQN 讓你懂了原理。但真正做專案時,沒有人會每次都從頭重寫訓練迴圈、replay buffer、target network——容易出錯,又難調到最佳。
stable-baselines3(SB3) 是 RL 界最常用的函式庫,把 DQN、PPO、A2C、SAC 等演算法封裝成幾行就能用、而且經過嚴格調校的實作。這一課,你會看到上一課整個訓練迴圈,濃縮成一行 model.learn()。
這堂課你會學到
- 用 PPO 三行訓練 CartPole:建立模型 →
learn()→predict() - SB3 的核心價值:介面統一——
PPO換成DQN只改一個名字,其餘不動 - 評估訓練成果:跑幾回合看平均得分(CartPole-v1 滿分 500)
- 開 TensorBoard:RL 的儀表板,訓練不順時第一個該看的地方
PPO 是什麼?
PPO(Proximal Policy Optimization) 是目前最通用、最好調的演算法,OpenAI 訓練 ChatGPT 的 RLHF 也是它。它屬於下一課要手刻的「策略梯度」家族,核心是「每次更新別偏離舊策略太多」的護欄——所以又穩又好用。這一課先把它當黑盒子用,下一課再拆開看它的根。
手刻 vs 現成:兩個都要會
- 手刻(第 02–03、05 課)讓你懂原理:出問題時知道哪裡壞、為什麼壞。
- 現成(這一課)讓你做得快:把精力花在環境設計與調參,而不是重造輪子。
兩者不衝突,是互補。會手刻的人用 SB3,跟只會 call API 的人用 SB3,遇到問題時的差距是巨大的。
💡 TensorBoard 的圖表(獎勵曲線、loss、explained variance…)是讀懂訓練健康度的關鍵。Colab 裡用
%tensorboard --logdir兩行就能內嵌互動面板。
#rl
#stable-baselines3
#ppo
#tensorboard
留言 0
留言載入中…