從 Q 表到 DQN · 用神經網路逼近 Q
Q 表碰到連續或巨大的狀態空間就爆了。DQN 的點子:用一個神經網路取代那張表。這堂課親手刻一個迷你 DQN,配上經驗回放與 target network,把它在 CartPole 上練起來。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
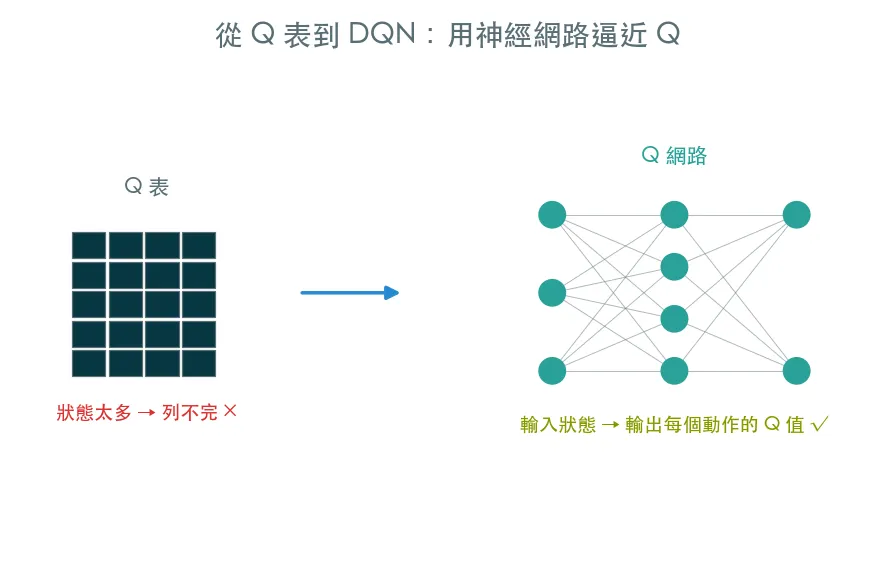
上一課的 Q 表有個過不去的坎:狀態一多就爆。CartPole 的觀察是 4 個連續數值,組合無限多,你永遠列不出一張表來。
DQN(Deep Q-Network) 的點子優雅得不得了:既然列不成表,就用一個神經網路來逼近這個函式——輸入狀態,輸出每個動作的 Q 值。表變成了網路,查表變成了前向傳播。這正是 2013 年 DeepMind 讓 AI 學會打 Atari 遊戲的那個突破。
這堂課你會學到
- 為什麼函式逼近能解決 Q 表的維度爆炸
- 親手刻一個 Q 網路(小型 MLP):吃狀態、吐每個動作的 Q 值
- 兩個讓 DQN 訓練不發散的關鍵工程:
- 經驗回放 replay buffer:把走過的經驗存起來、隨機抽批訓練,打散資料相關性
- target network:用一個慢半拍的網路複本算目標值,避免「自己追自己」震盪
- 畫出學習曲線,看報酬一路往上爬
為什麼要這兩個小技巧?
直接拿神經網路套上 Q-learning,訓練常常會劇烈震盪甚至崩掉——因為前後步的資料高度相關,而且目標值跟著網路一起變,像追自己的影子。經驗回放解決前者,target network 解決後者。理解這兩招,你就懂了現成 RL 函式庫底下到底在防什麼。
⚠️ 如果你的曲線爬到頂又崩回去——這不是 bug
很多人第一次跑會看到一個經典形狀:報酬一路爬到接近滿分 500,然後突然崩回一兩百、卡在那裡。
這不是 overfitting,也不是你寫錯,而是 DQN 惡名昭彰的不穩定性——災難性遺忘(catastrophic forgetting),幾乎是手刻 DQN 的招牌曲線。
三個主因,都跟程式有關:
- 經驗回放被「好回合」洗掉多樣性(最大主因):buffer 上限一萬筆,但 agent 變強後一個回合長達 ~500 步,兩三個好回合就把 buffer 塞滿,早期那些「快跌倒、要搶救」的失敗樣本被擠光——agent 於是忘了怎麼從危險姿勢救回來。
- Q 值過度估計:
max運算子天生高估(deadly triad:函數逼近 + bootstrapping + off-policy)。 - 訓練過頭、沒早停:RL 裡訓練越久 ≠ 越好,跑過巔峰策略會漂走。
所以這張圖其實是「對的」:峰值證明迷你 DQN 真的學得會,崩潰證明了為什麼真實系統要加穩定技巧(eval 早停存檔、Double DQN、更大的 buffer、gradient clipping、soft update)。下一課的 stable-baselines3 把這些都內建好了。
💡 這是整條軌道手刻難度最高的一課。撐過去,你會對「深度強化學習」這個詞徹底祛魅——它不是魔法,就是一個 MLP 加幾個穩定訓練的小技巧。下一課我們就用 stable-baselines3 把同樣的事一行搞定,但你已經知道那一行底下在做什麼、又在防什麼。
留言 0
留言載入中…