02 入門
手刻 Q-learning · 一張表學會走迷宮
最經典也最好懂的 RL 演算法。用一張 Q 表記住「在每個狀態做每個動作有多好」,搭配 Bellman 更新與 epsilon-greedy,讓 agent 在 FrozenLake 上學會從起點走到終點。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
上一課讓隨機策略上場,桿子總是很快倒下。這一課,agent 要真的開始學習了。我們從最經典、最直觀的 RL 演算法下手:Q-learning。
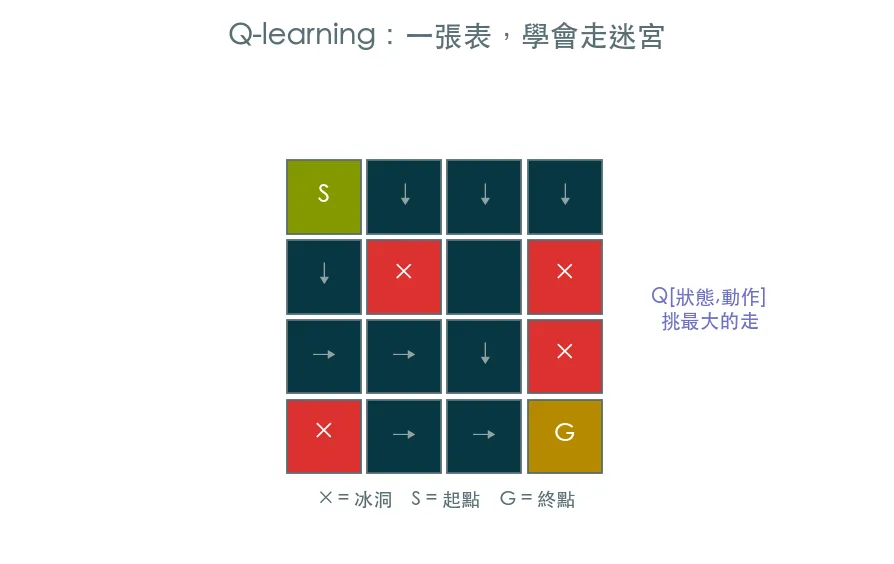
核心:一張 Q 表
Q[狀態, 動作]= 「在這個狀態做這個動作,預期能換到多少長期獎勵」。
學會這張表,策略就簡單到不行:每一步都挑 Q 值最大的動作。整個 Q-learning 就是在問:這張表的每一格,該填多少?
怎麼把表填對:Bellman 更新
agent 每走一步,就用實際發生的事修正一格:
Q[s,a] ← Q[s,a] + α · ( r + γ·max Q[s',·] − Q[s,a] )白話:「我原本以為這格值這麼多,但實際拿到 r、而且走到的新狀態 s' 看起來最好能再拿 max Q[s']——用這個現實,把我的估計往正確方向推一點點。」α 是學習率(推多用力),γ 是折扣因子(未來的獎勵打幾折)。
這堂課你會學到
- 用 NumPy 一張二維表手刻完整的 Q-learning
- epsilon-greedy:怎麼平衡「亂試探索」與「照目前最好的走」
- 把學到的策略畫成方向箭頭,看 agent 到底學到怎麼走
- 用學成的策略跑 100 回合,驗收成功率
練習場:FrozenLake
在結冰的湖面上,從起點走到終點、別掉進冰洞。我們先用不打滑版本(is_slippery=False),讓規律最單純——學成後成功率會接近 100%。想挑戰?把打滑打開,世界立刻變得隨機又困難,正好體會 RL 處理不確定性的威力。
💡 Q 表法的致命傷:狀態一多,表就爆了。FrozenLake 只有 16 格沒問題,但 CartPole 的連續狀態根本列不成表——這就是下一課 DQN 登場的理由。
#rl
#q-learning
#frozenlake
#gymnasium
留言 0
留言載入中…