01 入門
強化學習的世界觀 · 第一個 gym 環境
強化學習不看正確答案,而是讓 agent 在環境裡試錯、靠獎勵自己摸索。這堂課用經典的 CartPole 把 agent ⇄ environment 的迴圈跑起來,認識 gymnasium 的標準介面。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
歡迎來到 強化學習 → 手刻強化學習。
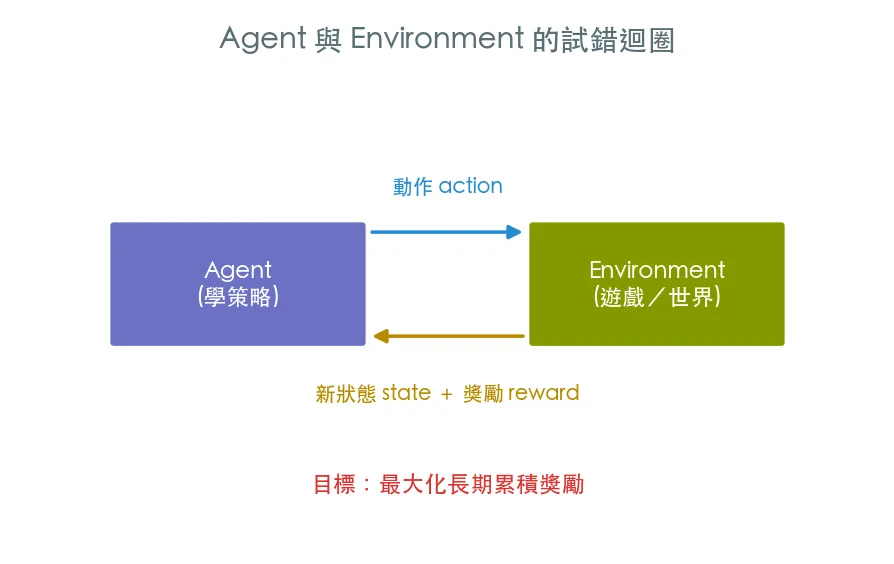
前面的軌道裡,模型都是看著「正確答案」學的——監督式學習有標籤、自監督有下一個字。強化學習(Reinforcement Learning, RL)換了一種完全不同的學法:沒有人告訴 agent 哪個動作才對,它只能在環境裡不斷試錯,靠一個「獎勵」訊號自己摸索出好策略。就像學騎腳踏車——沒有標準答案,跌幾次、抓到平衡感就會了。
一句話心智模型
RL 的世界 = Agent ⇄ Environment。 agent 看到狀態(state)、做出動作(action)、收到獎勵(reward) 與新狀態,如此反覆。它的唯一目標:最大化長期累積的獎勵。
注意「長期」兩個字——RL 最迷人也最難的地方,就是 agent 得學會為了將來的大獎,忍住眼前的小利。
這堂課你會學到
- 建立 agent ⇄ environment 試錯迴圈的心智模型
- 認識 gymnasium(OpenAI Gym 的後繼者)——RL 環境的事實標準
- 讀懂環境的兩個 space:觀察空間(agent 看得到什麼)與動作空間(agent 能做什麼)
- 用
reset()/step()跑一回合 CartPole(平衡一根桿子),親眼看「還沒學會」長什麼樣
為什麼從 CartPole 開始?
CartPole 是 RL 的「Hello World」:推動一台小車,讓上面的桿子不要倒。觀察只有 4 個數字、動作只有「左推/右推」兩個,簡單到能在筆電上秒跑,卻完整涵蓋 RL 的所有要素。這堂課先讓隨機策略上場——你會看到桿子十幾步就倒——這個「撐不久」正是後面每一課要解決的問題。
👉 建議先學完
ml/pytorch(熟悉張量與神經網路),後面手刻 DQN 與策略梯度會用到。這一課純 CPU 秒跑,Colab 不用開 GPU。
#rl
#gymnasium
#cartpole
#reinforcement-learning
留言 0
留言載入中…