RAG Agent:讓 agent 查得到事實
LLM 會自信地瞎掰它沒學過的事。RAG(檢索增強生成)給它一個外部知識庫,先檢索相關資料、再根據資料回答。這課手刻 embedding 檢索,做一個會在需要時自己去查資料的 agent。
這堂課的完整程式碼在 Jupyter notebook 裡。點下面按鈕在 Colab 開啟,就能直接執行、修改、實驗——你的修改不會動到原檔。
LLM 最危險的毛病是幻覺:它會用一樣自信的語氣,說出它根本沒學過、或記錯的事實。問一個小型 Qwen「某個冷門主題的細節」,它八成會編一個聽起來很合理、但錯的答案。RAG 就是治這個病的藥。
RAG = 先查、再答
RAG(Retrieval-Augmented Generation,檢索增強生成) 的想法很直白:
別讓模型憑記憶回答。先從一個外部知識庫裡檢索出跟問題相關的資料,把這些資料連同問題一起餵給模型,要求它根據這些資料作答。
模型不再靠「背過的、可能記錯的」記憶,而是靠「眼前這份、我們提供的」資料——答案因此有依據(grounded),還能附上出處。
怎麼「檢索相關資料」?用 embedding
關鍵是怎麼從一堆文件裡找出「跟問題相關」的幾篇。靠關鍵字比對太脆弱(同義詞就漏了)。正解是 embedding(語意向量):
- 把每篇文件、還有問題,各自轉成一個向量(用一個多語 embedding 模型,CPU 就能跑)。
- 語意相近的文字,向量也相近。算問題向量和每篇文件向量的餘弦相似度,取最相近的幾篇,就是檢索結果。
這個「向量化 → 算相似度 → 取 top-k」的檢索迴圈,我們自己用 numpy 手刻——不過幾行,而且看得一清二楚。
RAG Agent:讓模型自己決定何時查
更進一步:不是每個問題都需要查資料(「3 加 5 等於幾」就不用)。所以我們把檢索包成一支工具 retrieve(query),接回前面的 ReAct agent——讓模型自己判斷「這題我得查一下」才去呼叫檢索,查完再根據結果回答。檢索從一個固定步驟,變成 agent 工具箱裡的一個選項。
這堂課你會學到
- 理解 RAG 為什麼能治幻覺:先檢索、再 grounding
- 用多語 embedding 模型把一個內嵌的小知識庫向量化(零下載、自成一體)
- 手刻餘弦相似度檢索(numpy),取出 top-k 相關文件
- 把檢索包成
retrieve工具接回 ReAct,做一個會自己決定何時查資料的 agent - 對照:沒 RAG 時模型瞎掰,有 RAG 後答對且附出處
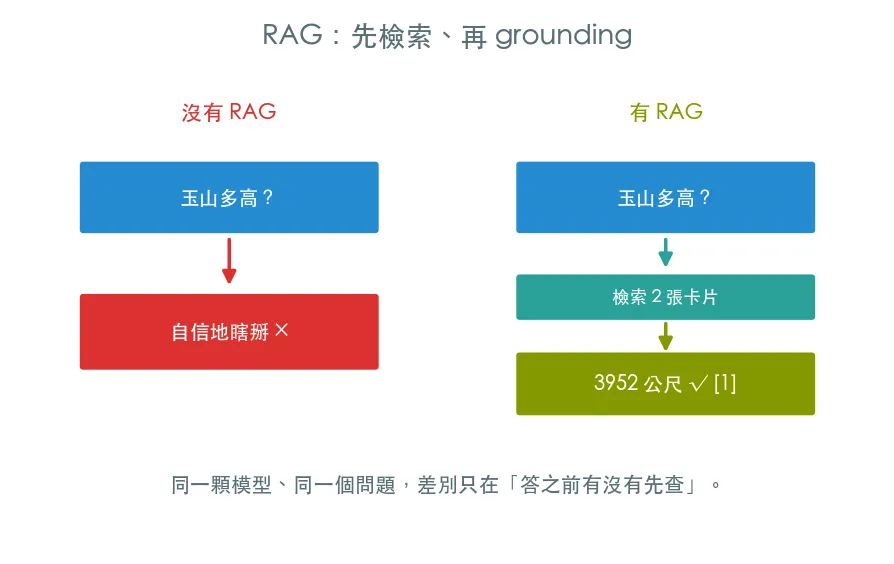
瞎掰 vs 有憑有據
預覽圖把這課畫成左右對照:左邊「沒有 RAG」——問題直接進模型,出來一個自信但錯誤的幻覺答案;右邊「有 RAG」——問題先去知識庫檢索出最相關的兩張卡片,連同問題一起進模型,出來一個正確、且標注了出處的答案。同一顆模型、同一個問題,差別只在「答之前有沒有先查」。
👉 在 Colab 裡往知識庫加幾張你自己的卡片(例如你專案的設定細節),問 agent——體會 RAG 怎麼讓一個泛用模型瞬間「懂」它從沒訓練過的私有知識。
留言 0
留言載入中…