[AI 演進史 Part 2] 視覺的爆發:從 GAN 到 Stable Diffusion
2026年1月11日 · wemee
![[AI 演進史 Part 2] 視覺的爆發:從 GAN 到 Stable Diffusion](/images/blog/ai-evolution-part2-creation.webp)
在 上一篇 文章中,我們聊到了 Deep Learning 如何稱霸了分類 (Classification) 與預測的世界。
那時候的 AI,像是一個超級嚴謹的鑒定師。你給它一張圖,它能告訴你:「這是貓,機率 99.8%」。 但如果你問它:「那你能不能畫一隻貓給我看?」 它會當機給你看。因為它是判別式模型 (Discriminative Model),它懂得「分辨」,但不懂「創造」。
直到一個關鍵技術的出現,打開了潘朵拉的盒子。
神之間的對決:GAN (生成對抗網路)
Ian Goodfellow 在 2014 年提出 GAN (Generative Adversarial Network) 時,整個 AI 圈子都瘋了。
這個點子太天才了:既然我們很難直接教電腦畫畫,不如讓兩個 AI 互相打架?
- Generator (生成器):負責製造偽造品(畫假圖)。
- Discriminator (判別器):負責抓假貨(分辨這張圖是真人畫的還是機器生成的)。
一開始生成器畫得像鬼畫符,判別器一眼就識破。生成器為了騙過判別器,只好越畫越好;判別器為了不被騙,也只好眼力越來越尖。 最終達到一個納什均衡 (Nash Equilibrium),生成器畫出來的圖,連最強的判別器都分不出來。

那段時間我也沉迷於此。看著螢幕上那一團雜訊,隨著訓練 epoch 的增加,慢慢浮現出人的五官,那種感覺就像是在看著一個生命在數位世界裡誕生。
潛在空間的魔法:AE, VAE 與 StyleGAN
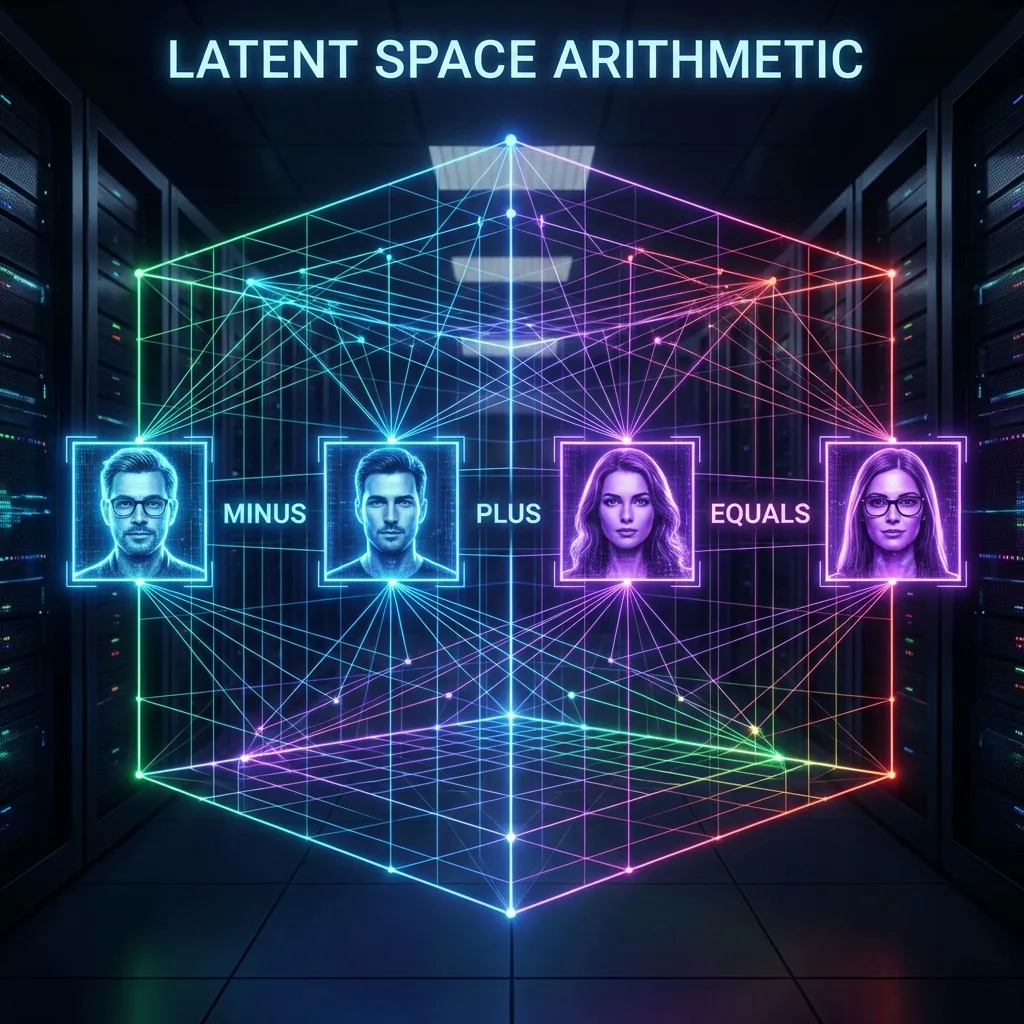
後來我們開始玩弄更深奧的東西:Latent Space (潛在空間)。
我們發現,所有的圖像都可以被壓縮成一組數學向量 (Vector)。
- 如果你把「戴眼鏡男人」的向量,減去「男人」的向量,再加上「女人」的向量。
- 神奇的事情發生了:AI 生成了一張「戴眼鏡女人」的照片。
StyleGAN 把這件事推到了極致。我們發現可以做出超高解析度、毛孔清晰可見的人臉,而且這些人根本不存在於世界上 (thispersondoesnotexist.com)。
但這時候的生成式 AI 還有一個致命傷:難訓練。GAN 很容易「崩潰 (Mode Collapse)」,訓練十次有九次會失敗,參數超難調。
擴散模型的革命:Diffusion Model
就在我們對 GAN 又愛又恨的時候,Diffusion Model (擴散模型) 橫空出世。
它的原理完全不同:它不是「無中生有」,而是「去噪 (Denoise)」。 想像這是一個要把墨汁從清水中分離出來的過程。你給它一張充滿雜訊 (Noise) 的圖片,AI 的任務是一點一點地把雜訊拿掉,還原出原本的圖像。
這聽起來很慢,但效果驚人的好,而且訓練非常穩定。

緊接著 Stable Diffusion 開源了。這真的是核彈級的消息。 以前我們要在超級電腦上跑的模型,現在可以在你我的家用顯卡上跑。加上 Prompt (提示詞) 的引入,所有人都變成了藝術家。
看著我自己在電腦上輸入 “A cyberpunk city in the rain”,幾秒鐘後一張精美絕倫的畫作出現在螢幕上。我意識到,視覺創作的壁壘被打破了。
接下來呢?
我們解決了「分辨」(CNN),解決了「視覺創造」(Diffusion)。 這時候的 AI 已經很強大了,但它還缺了一塊最重要的拼圖。
它還不懂我們人類最核心的智慧載體——語言。 它能畫出美麗的圖,但它聽不懂複雜的邏輯,它寫不出一首詩,它無法理解上下文的幽默。
直到那一篇著名的論文《Attention Is All You Need》出現,Transformer 架構誕生,為後來的大語言模型 (LLM) 鋪平了道路…